

In HHH-L mode, Hadoop MapReduce runs over HDFS that is integrated with parallel file system (e.g. Lustre). This is a hybrid mode that stores data in both local storage and Lustre. Lustre provides fault-tolerance in this mode. Therefore, HDFS replication is not required. We evaluate our package with this setup and provide performance comparisons here. For detailed configuration and setup, please refer to our userguide.
TestDFSIO Write and TestDFSIO Read
TestDFSIO Write
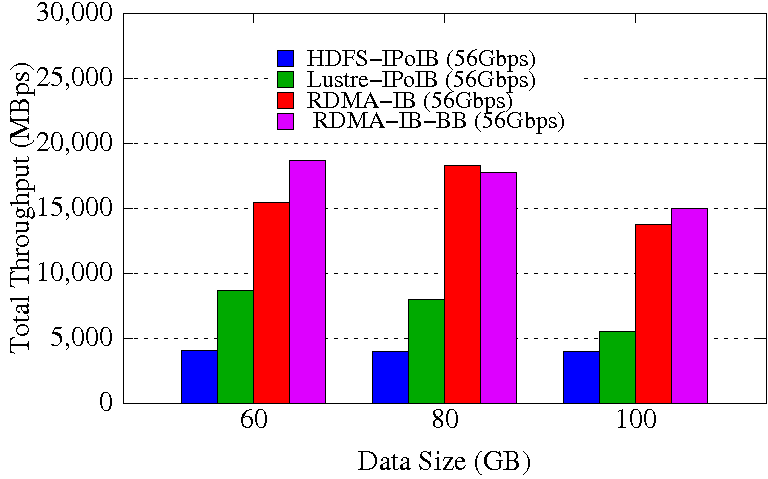
TestDFSIO Read
Experimental Testbed: Each compute node in this cluster has two twelve-core Intel Xeon E5-2680v3 processors, 128GB DDR4 DRAM, and 320GB of local SSD with CentOS operating system. Each node has 64GB of RAM disk capacity. The network topology in this cluster is 56Gbps FDR InfiniBand with rack-level full bisection bandwidth and 4:1 oversubscription cross-rack bandwidth.
The TestDFSIO experiments are performed in 16 DataNodes with a total of 64 maps. HDFS block size is kept to 128 MB. The NameNode runs in a different node of the Hadoop cluster and the benchmark is run in the NameNode. The RDMA-IB design improves the write throughput by up to 4.58x over HDFS-IPoIB (56Gbps). RDMA-IB-BB design has an improvement of 4.66x compared to HDFS-IPoIB (56Gbps). The performance improvement for read throughput is up to 29.1% over Lustre-IPoIB (56Gbps). RDMA-IB design has an improvement of 27.6% over Lustre-IPoIB (56Gbps).
RandomWriter and Sort
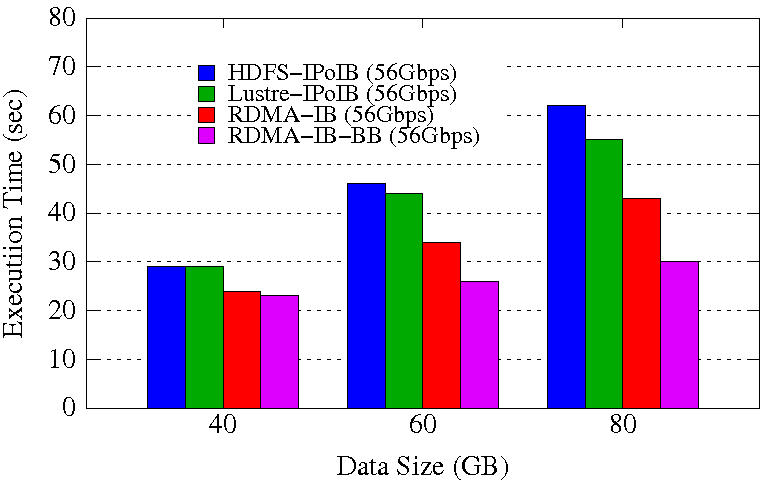
RandomWriter Execution Time
Sort Execution Time
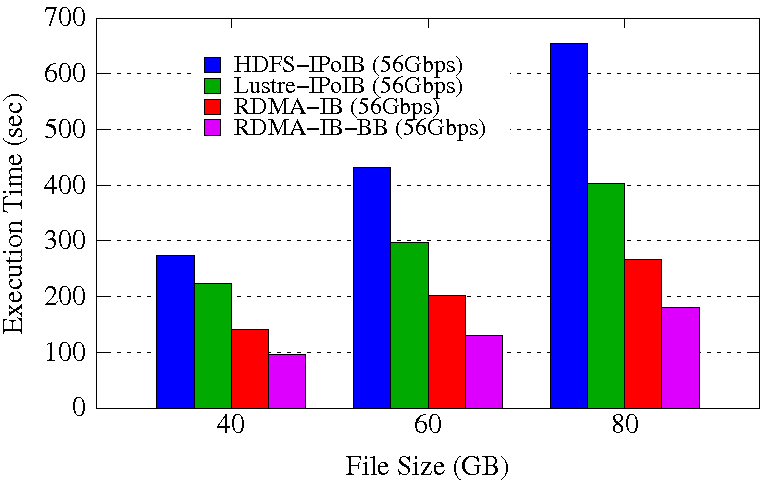
Experimental Testbed: Each compute node in this cluster has two twelve-core Intel Xeon E5-2680v3 processors, 128GB DDR4 DRAM, and 320GB of local SSD with CentOS operating system. Each node has 64GB of RAM disk capacity. The network topology in this cluster is 56Gbps FDR InfiniBand with rack-level full bisection bandwidth and 4:1 oversubscription cross-rack bandwidth.
These experiments are performed in 16 DataNodes with a total of 128 maps. For Sort, 28 reducers are launched. HDFS block size is kept to 256 MB. Each NodeManager is configured to run with 6 concurrent containers assigning a minimum of 1.5GB memory per container. The NameNode runs in a different node of the Hadoop cluster.
The RDMA-IB design improves the job execution time of RandomWriter by 30% comapred to HDFS-IPoIB (56Gbps) and 22% compared to Lustre-IPoIB (56Gbps). The RDMA-IB-BB design improves the job execution time of RandomWriter by 51% comapred to HDFS-IPoIB (56Gbps) and 45% compared to Lustre-IPoIB (56Gbps). For Sort, RDMA-IB has an improvement of 59% compared to HDFS-IPoIB (56Gbps) and 36% compared to Lustre-IPoIB (56Gbps). The RDMA-IB-BB design has an improvement of 72% compared to HDFS-IPoIB (56Gbps) and 57% compared to Lustre-IPoIB (56Gbps).
TestDFSIO Write and TestDFSIO Read
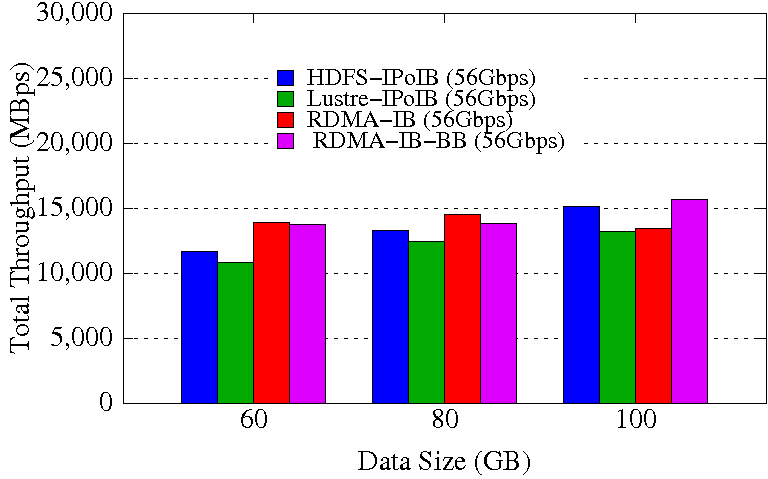
TestDFSIO Write
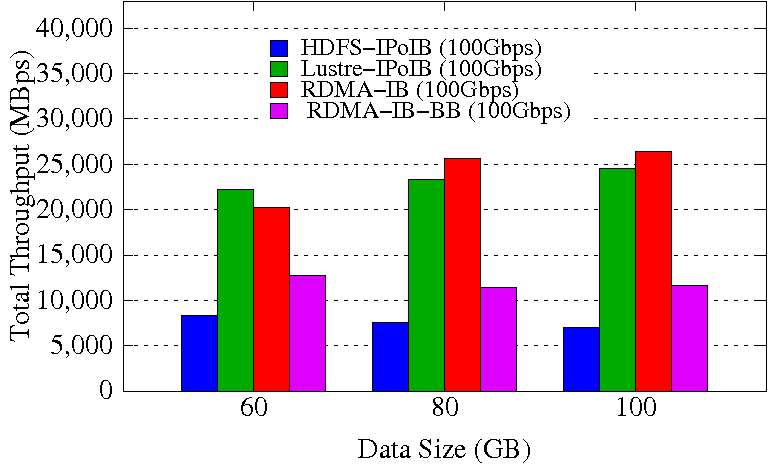
TestDFSIO Read
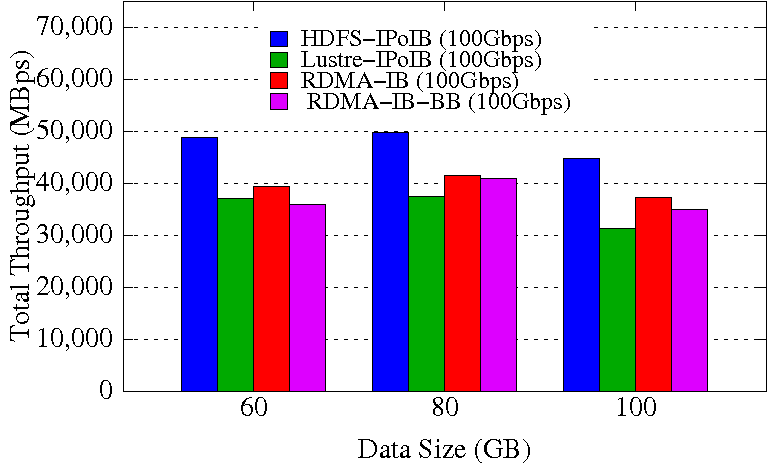
Experimental Testbed: Each node in OSU-RI2 has two fourteen Core Xeon E5-2680v4 processors at 2.4 GHz and 512 GB main memory. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
These experiments are performed in 8 DataNodes with a total of 64 maps and 32 reduces. Each DataNode has a single 2TB HDD, single 400GB PCIe SSD, and 252GB of RAM disk. HDFS block size is kept to 256 MB. Each NodeManager is configured to run with 12 concurrent containers assigning a minimum of 1.5GB memory per container. The NameNode runs in a different node of the Hadoop cluster. 70% of the RAM disk is used for HHH data storage.
The RDMA-IB design improves the write throughput by up to 3.79x over HDFS-IPoIB (100Gbps). RDMA-IB-BB design has an improvement of 1.66x compared to HDFS-IPoIB (100Gbps). The performance improvement for read throughput is up to 18.9% over Lustre-IPoIB (100Gbps). RDMA-IB-BB design has an improvement of 11.1% over Lustre-IPoIB (100Gbps).
RandomWriter and Sort
RandomWriter Execution Time
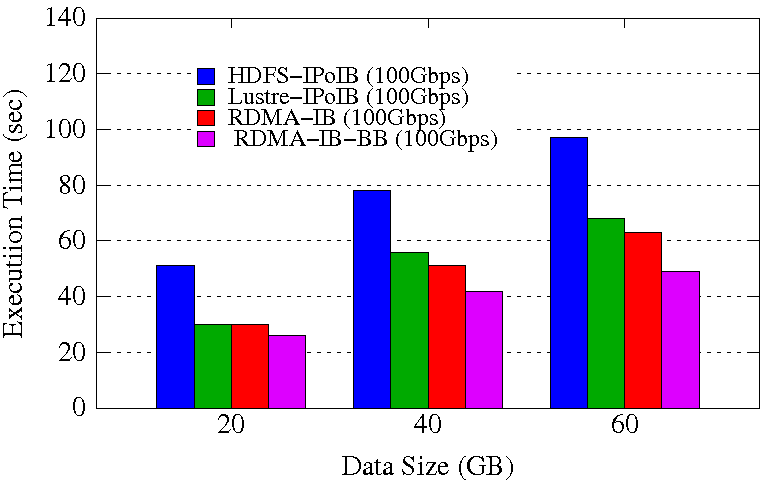
Sort Execution Time
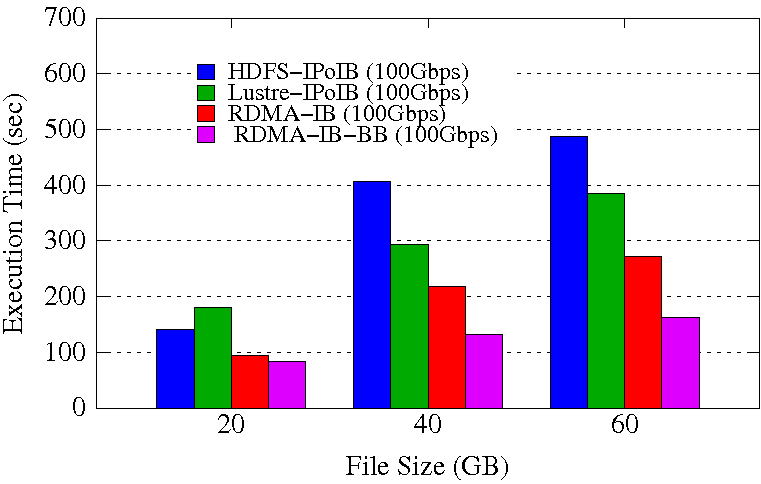
Experimental Testbed: Each node in OSU-RI2 has two fourteen Core Xeon E5-2680v4 processors at 2.4 GHz and 512 GB main memory. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
These experiments are performed in 8 DataNodes with a total of 64 maps and 32 reduces. Each DataNode has a single 2TB HDD, single 400GB PCIe SSD, and 252GB of RAM disk. HDFS block size is kept to 256 MB. Each NodeManager is configured to run with 12 concurrent containers assigning a minimum of 1.5GB memory per container. The NameNode runs in a different node of the Hadoop cluster. 70% of the RAM disk is used for HHH data storage.
The RDMA-IB design improves the job execution time of RandomWriter by 41% comapred to HDFS-IPoIB (100Gbps) and 9% compared to Lustre-IPoIB (100Gbps). The RDMA-IB-BB design improves the job execution time of RandomWriter by 49% comapred to HDFS-IPoIB (100Gbps) and 28% compared to Lustre-IPoIB (100Gbps). For Sort, RDMA-IB has an improvement of 46% compared to HDFS-IPoIB (100Gbps) and 47% compared to Lustre-IPoIB (100Gbps). The RDMA-IB-BB design has an improvement of 66% compared to HDFS-IPoIB (100Gbps) and 57% compared to Lustre-IPoIB (100Gbps).

