

RDMA-based Apache Hadoop 2.x (RDMA-Hadoop-2.x)
RDMA for Apache Hadoop 2.x is a high-performance design of Hadoop over RDMA-enabled Interconnects. This version of RDMA for Apache Hadoop 2.x 1.3.5 is based on Apache Hadoop 2.8.0 and is compliant with Apache Hadoop 2.8.0, Hortonworks Data Platform (HDP) 2.3.0.0, and Cloudera Distribution of Hadoop (CDH) 5.6.0 APIs and applications.
The figure below presents a high-level architecture of RDMA for Apache Hadoop 2.x. In this package, many different modes have been included that can be enabled/disabled to obtain performance benefits for different kinds of applications in different Hadoop environments. This package can be configured to run MapReduce jobs on top of HDFS as well as Lustre.
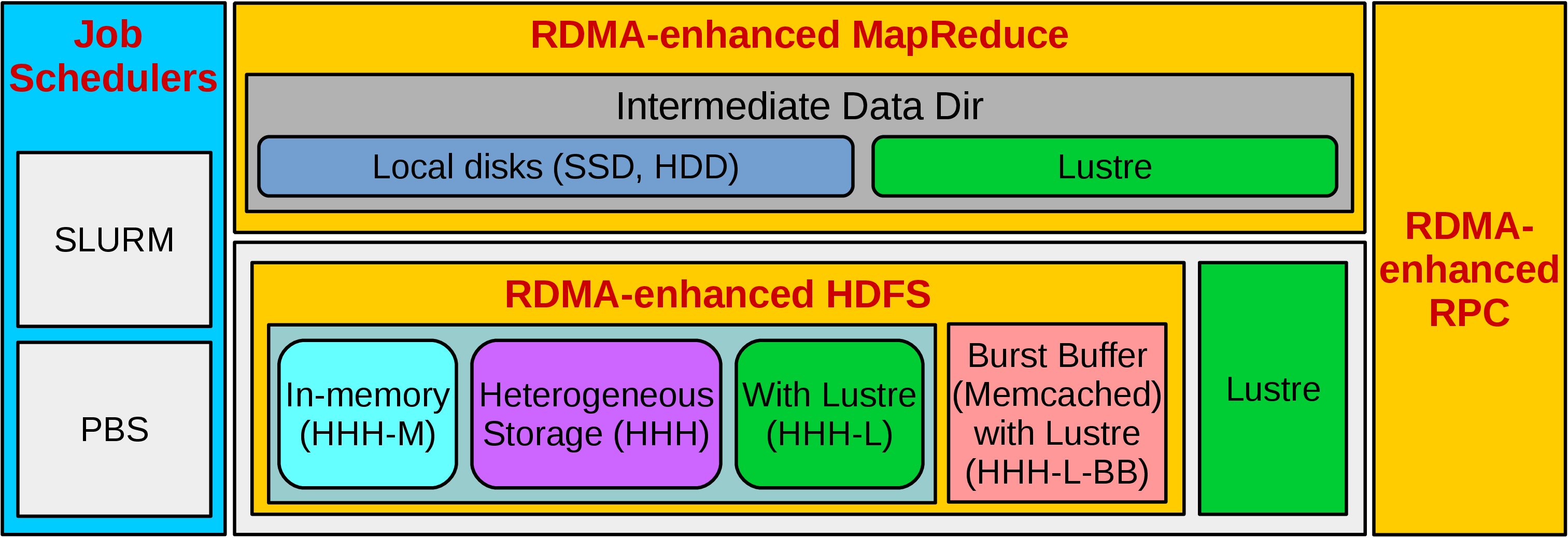
Following are the different modes that are included in our package.
- HHH: Heterogeneous storage devices with hybrid replication schemes are supported in this mode of operation to have better fault-tolerance as well as performance. This mode is enabled by default in the package.
- HHH-M: A high-performance in-memory based setup has been introduced in this package that can be utilized to perform all I/O operations in-memory and obtain as much performance benefit as possible.
- HHH-L: With parallel file systems integrated, HHH-L mode can take advantage of the Lustre available in the cluster.
- HHH-L-BB: HHH-L-BB mode deploys a Memcached-based burst buffer system to reduce the bandwidth bottleneck of shared file system access. The burst buffer design is hosted by Memcached servers, each of which has a local SSD.
- MapReduce over Lustre, with/without local disks: Besides, HDFS based solutions, this package also provides support to run MapReduce jobs on top of Lustre alone. Here, two different modes are introduced: with local disks and without local disks.
- Running with Slurm and PBS: Supports deploying RDMA for Apache Hadoop 2.x with Slurm and PBS in different running modes (HHH, HHH-M, HHH-L, and MapReduce over Lustre).
MVAPICH2-based Apache Spark (MPI4Spark 0.3)
MPI4Spark v0.3 supports both the standalone and YARN cluster managers. This is done by relying on the Multiple-Program-Multiple-Data (MPMD) MPI launcher mode to launch executor processes. The architecture of MPI4Spark remains that same with the underlying MPI-based Netty at its core.
The following figures showcase the new YARN cluster manager design whereby only executor processes are launched in an MPI environment. The figure to the right highlights the implementation which relies on the linux shared file system. This is different than the standalone cluster manager design where all components of the Spark cluster are launched through the MPI launcher.
MPI4Spark+YARN Design
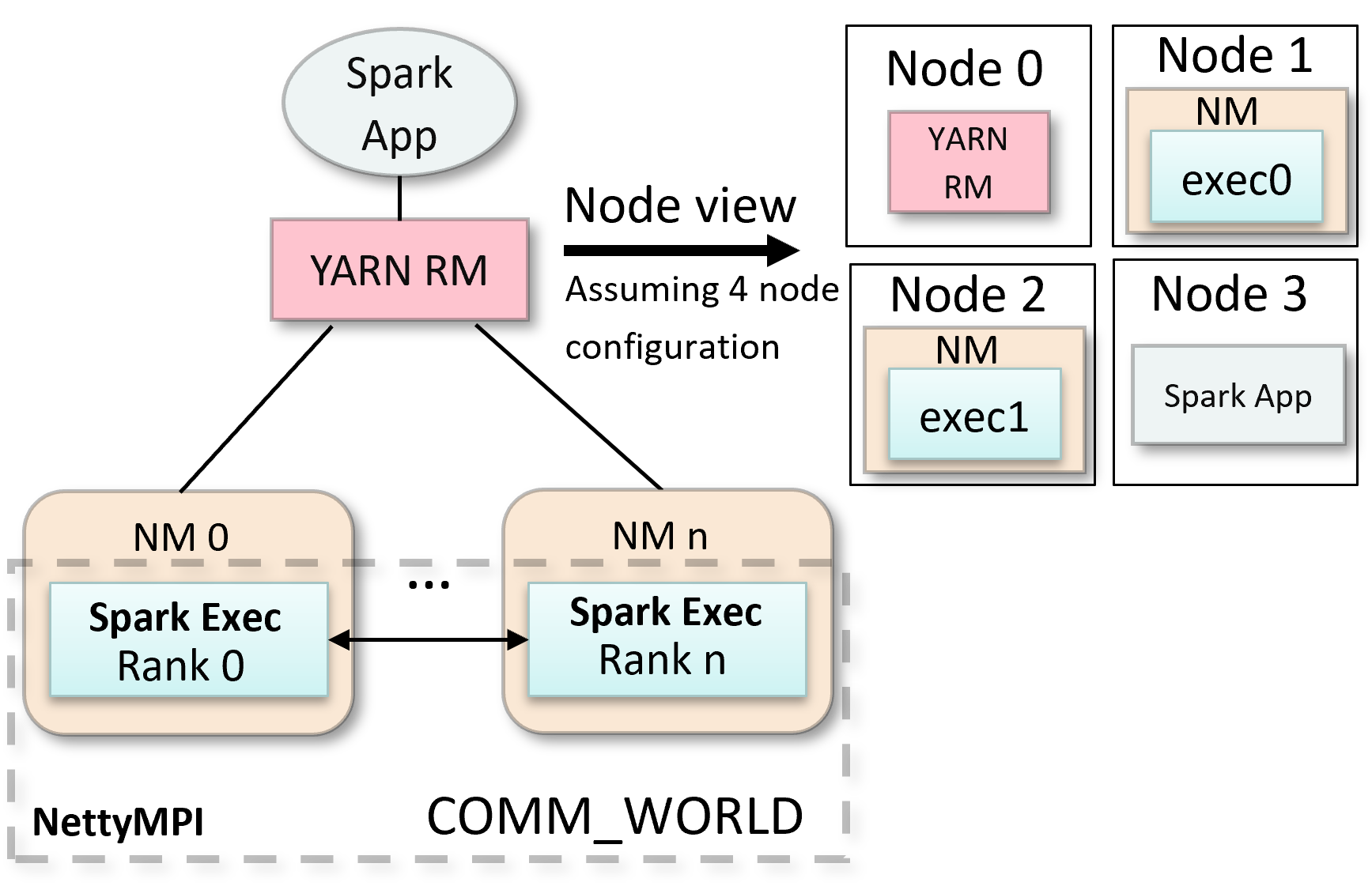
MPI4Spark+YARN Implementation
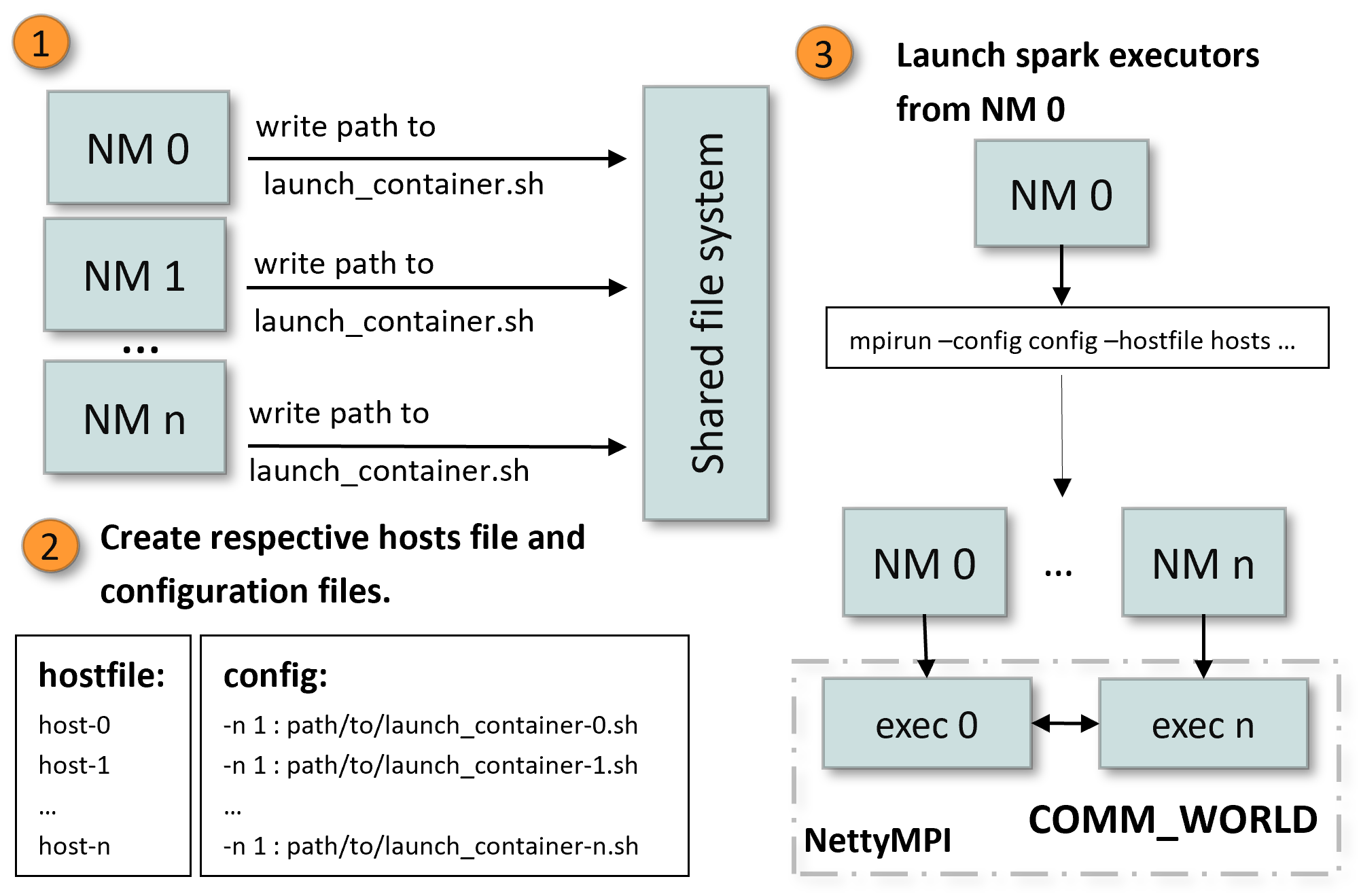
Step 1 is concerned with writing the paths of the YARN executor launcher scripts to a shared location visible to all NodeManagers. As mentioned earlier, This is done in the SPARK_HOME directory inside a sub-directory called mpmd_config. Step 2 executes the setup-and-run-yarn-mpmd.sh script which creates the mpmd.config and hostfile files, and step 3 launches the executor containers in their respective NodeManager nodes through MPI. Launching of the executors processes on their respective NodeManager nodes is taken care by the MPI launcher as long as the hostfile and mpmd.config file were properly generated.
Dept of Computer Science and Engineering
2001-2025 NBCL. All rights reserved.


2015 Neil Avenue
Columbus, OH 43210