

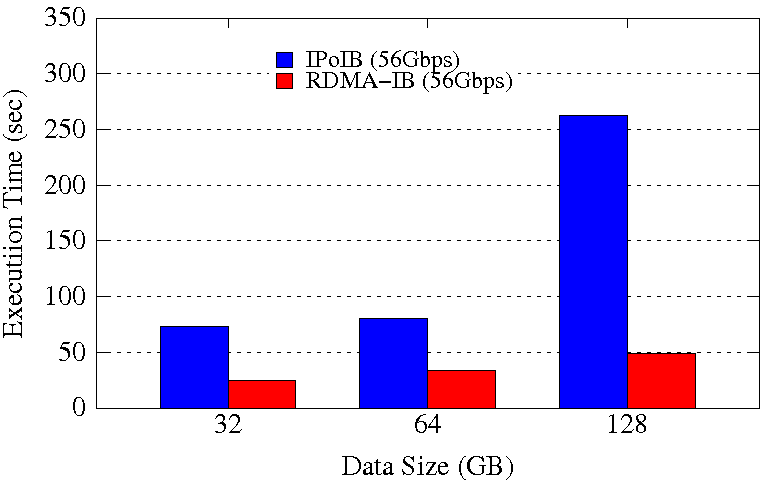
GroupBy Execution Time on 32 Worker Nodes / 768 Cores
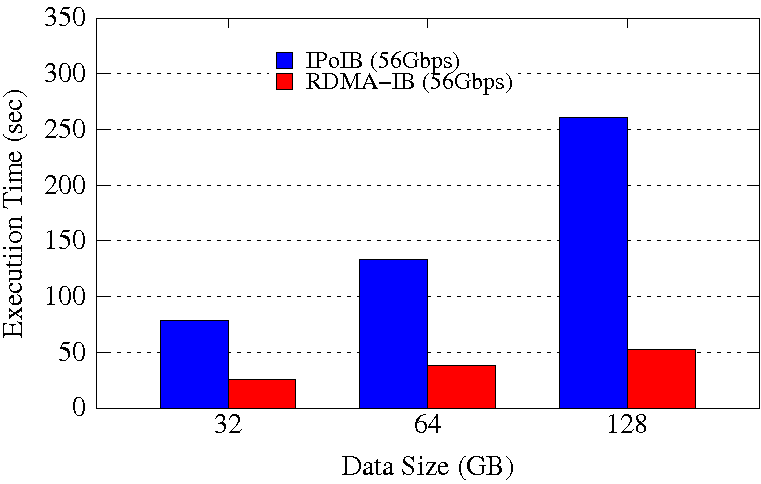
SortBy Execution Time on 32 Worker Nodes / 768 Cores
Experimental Testbed: Each compute node in this cluster has two twelve-core Intel Xeon E5-2680v3 processors, 128GB DDR4 DRAM, and 320GB of local SSD with CentOS operating system. The network topology in this cluster is 56Gbps FDR InfiniBand with rack-level full bisection bandwidth and 4:1 oversubscription cross-rack bandwidth.
These experiments are performed on 32 Worker Nodes with a total of 768 maps and 768 reduces so that the job is run with full subscription on 768 Cores in the cluster. Spark is run in Standalone mode. Configuration used is spark_worker_memory=96GB, spark_worker_cores=24, spark_executor_instances=1. SSD is used for Spark Local and Work data.
The RDMA-IB design improves the job execution time of GroupBy by 58% - 82% and SortBy by 68% - 80% compared to IPoIB (56Gbps). The improvement is highest for 128GB datasize for both the workloads.
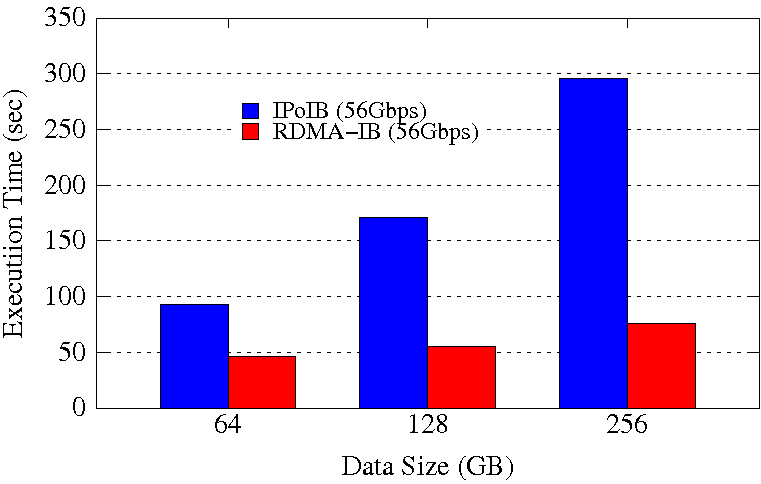
GroupBy Execution Time on 64 Worker Nodes / 1536 Cores
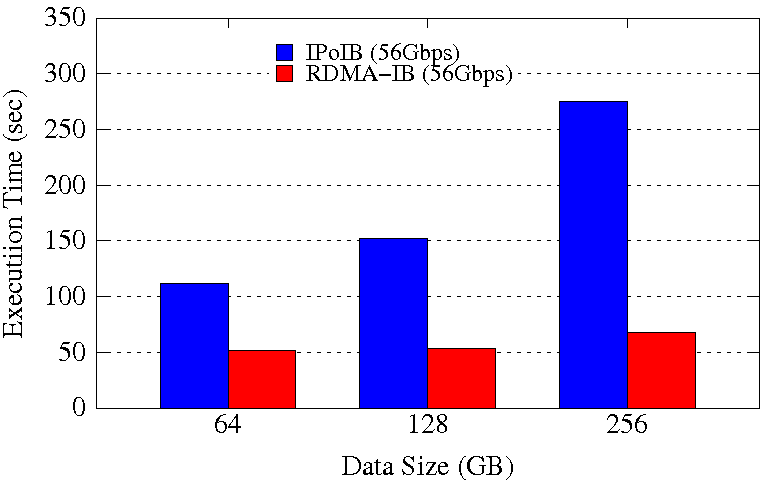
SortBy Execution Time on 64 Worker Nodes / 1536 Cores
Experimental Testbed: Each compute node in this cluster has two twelve-core Intel Xeon E5-2680v3 processors, 128GB DDR4 DRAM, and 320GB of local SSD with CentOS operating system. The network topology in this cluster is 56Gbps FDR InfiniBand with rack-level full bisection bandwidth and 4:1 oversubscription cross-rack bandwidth.
These experiments are performed on 64 Worker Nodes with a total of 1536 maps and 1536 reduces so that the job is run with full subscription on 1536 Cores in the cluster. Spark is run in Standalone mode. Configuration used is spark_worker_memory=96GB, spark_worker_cores=24, spark_executor_instances=1. SSD is used for Spark Local and Work data.
The RDMA-IB design improves the average job execution time of GroupBy by 46%-76% and SortBy by 54%-75% compared to IPoIB (56Gbps). The improvement is highest for 256GB datasize for both the workloads.

