

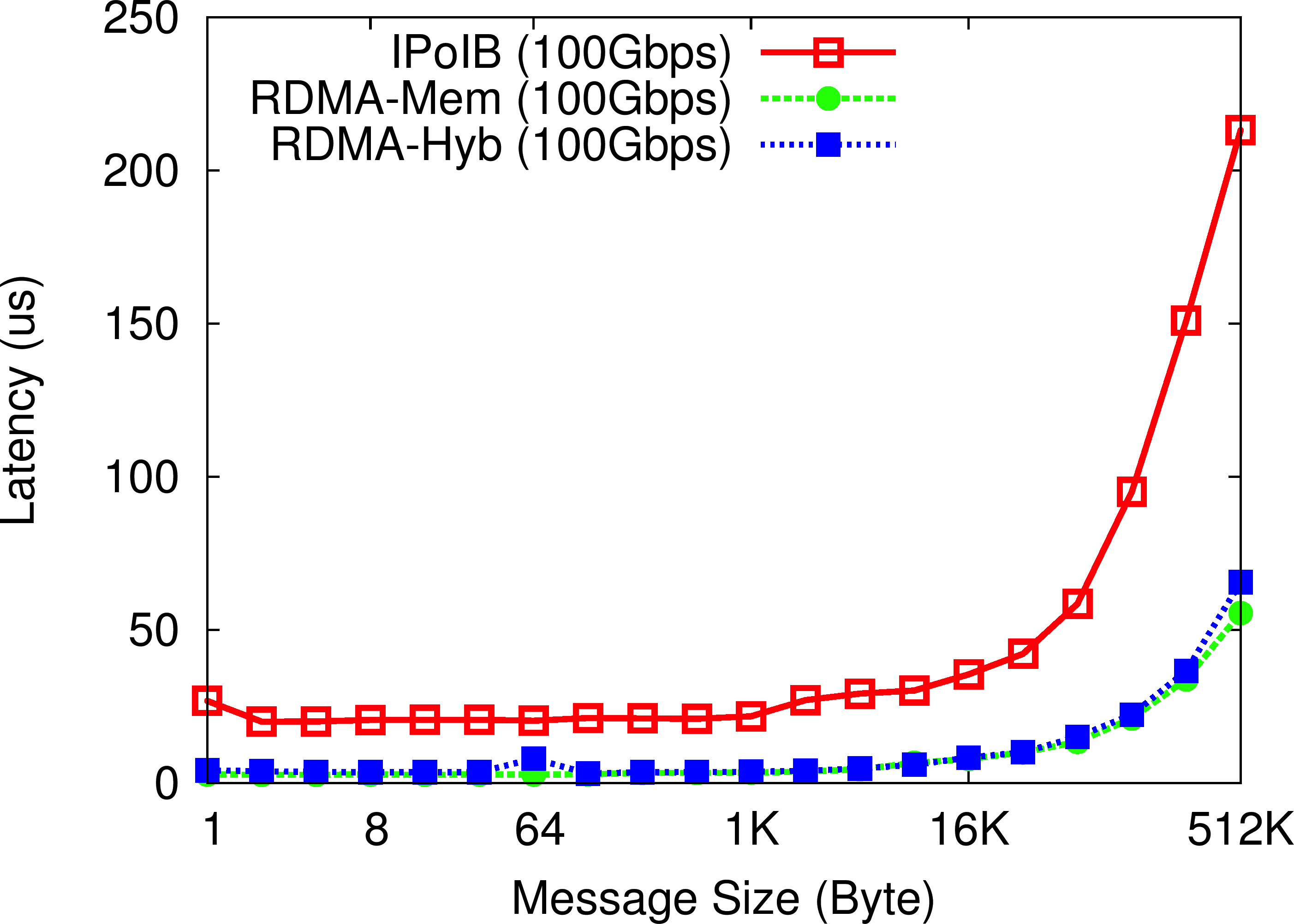
OHB Set Micro-benchmark
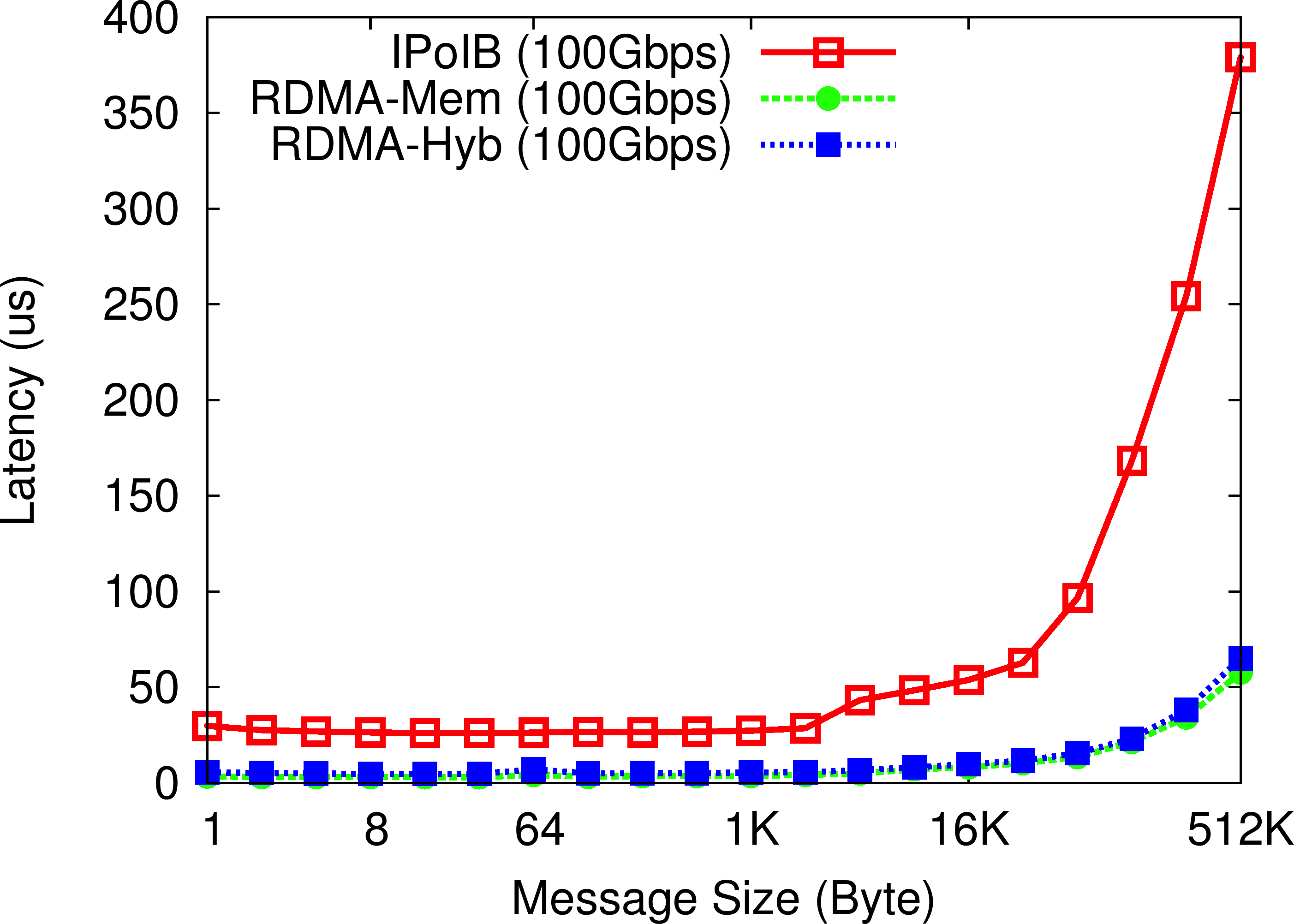
OHB Get Micro-benchmark
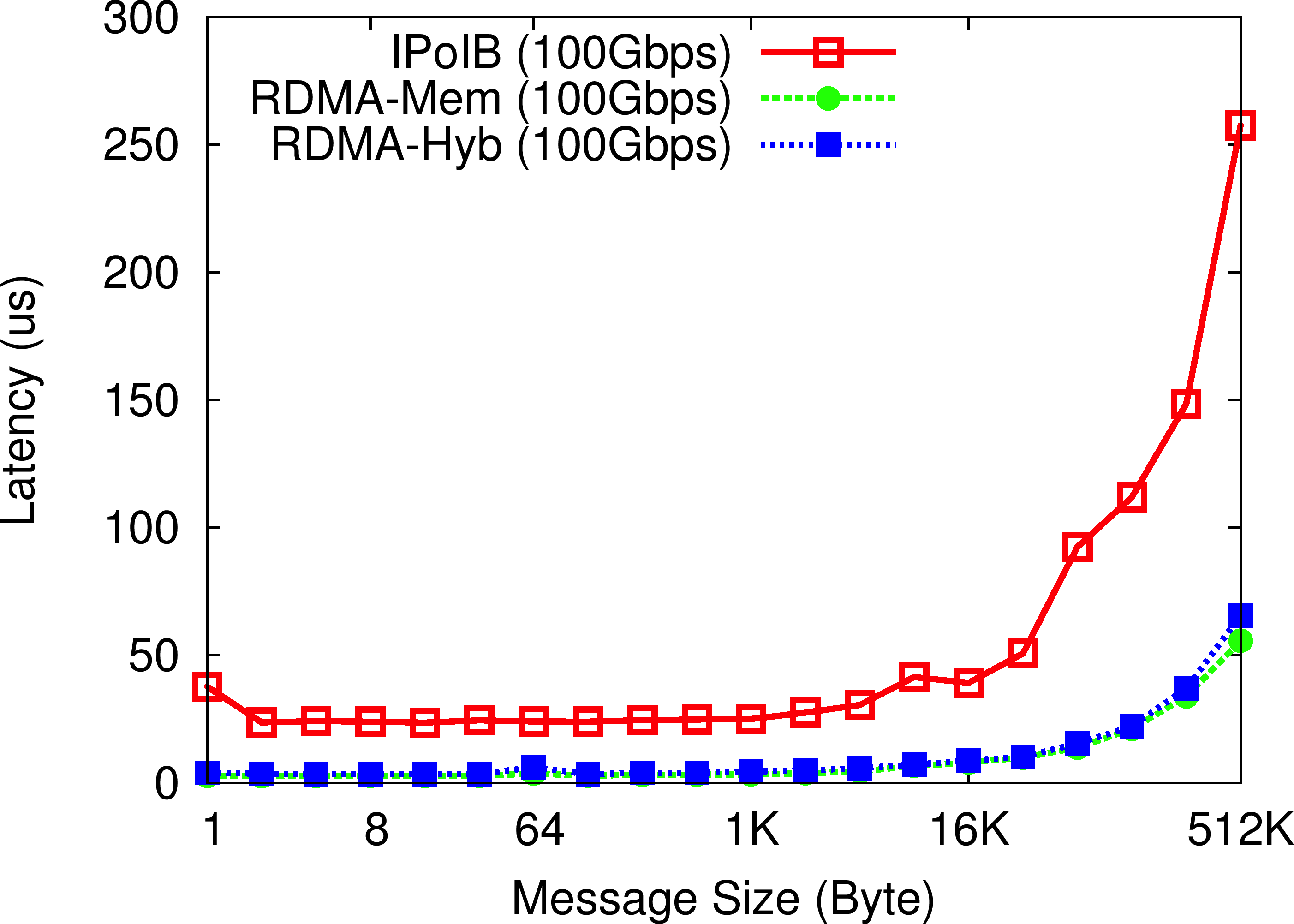
OHB Mix Micro-benchmark
Experimental Testbed (OSU - RI2 Cluster): Each storage node on OSU-RI2 has two fourteen Core Xeon E5-2680v4 processors at 2.4 GHz, 512 GB main memory, and a single 400GB PCIe SSD. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
These experiments are performed with a single Memcached server running with 32 GB of memory and a single Memcached client node.
In the OHB Set Micro-benchmark, the Memcached client repeatedly sets an item of a particular size on the Memcached server. The RDMA-enhanced Memcached design (both In-memory and SSD-based Hybrid) improves the latency of set operations by up to 5.8X over default Memcached running over IPoIB (100Gbps).
In the OHB Get Micro-benchmark, the Memcached client repeatedly gets an item of a particular size from the Memcached server. Compared to IPoIB (100Gbps), the RDMA-enhanced Memcached design (both In-memory and SSD-based Hybrid) improves the latency of get operations by more than 4-6.3X.
In the OHB Mix Micro-benchmark, the Memcached client repeatedly sets and gets an item of a particular size on the Memcached server, with a read/write mix of 90/10. We can observe that the RDMA-enhanced Memcached design (both In-memory and SSD-based Hybrid) improves the latency of set operations by more than 3.8-6.7X as compared to default Memcached over IPoIB (100Gbps).
OHB Hybrid Micro-benchmark with Zipf Pattern
OHB Hybrid Micro-benchmark with Uniform Pattern
OHB Hybrid Micro-benchmark Success Rate
Experimental Testbed (OSU - RI2 Cluster): Each storage node on OSU-RI2 has two fourteen Core Xeon E5-2680v4 processors at 2.4 GHz, 512 GB main memory, and a single 400GB PCIe SSD. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
These experiments are performed with a single Memcached server and a single Memcached client node.
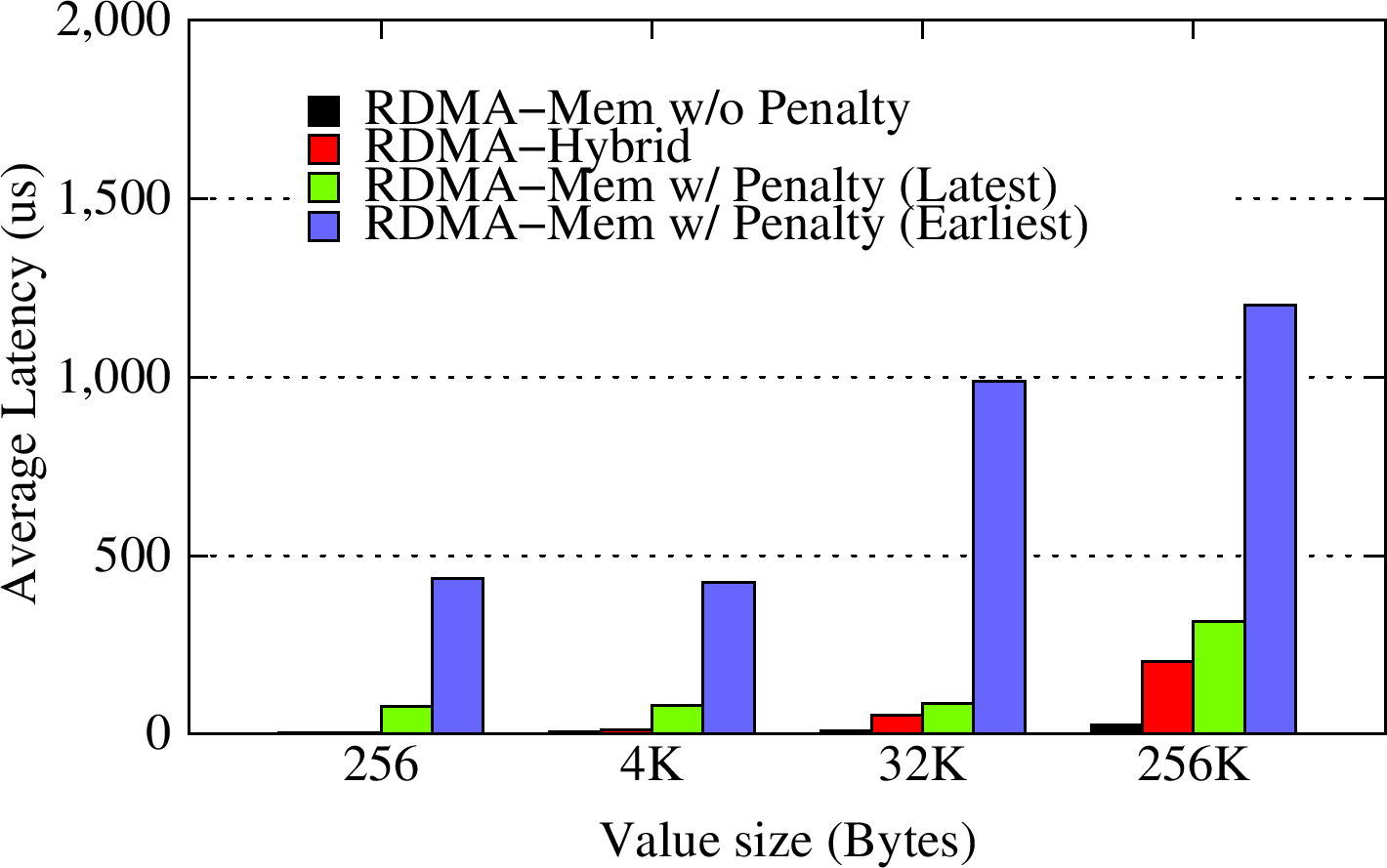
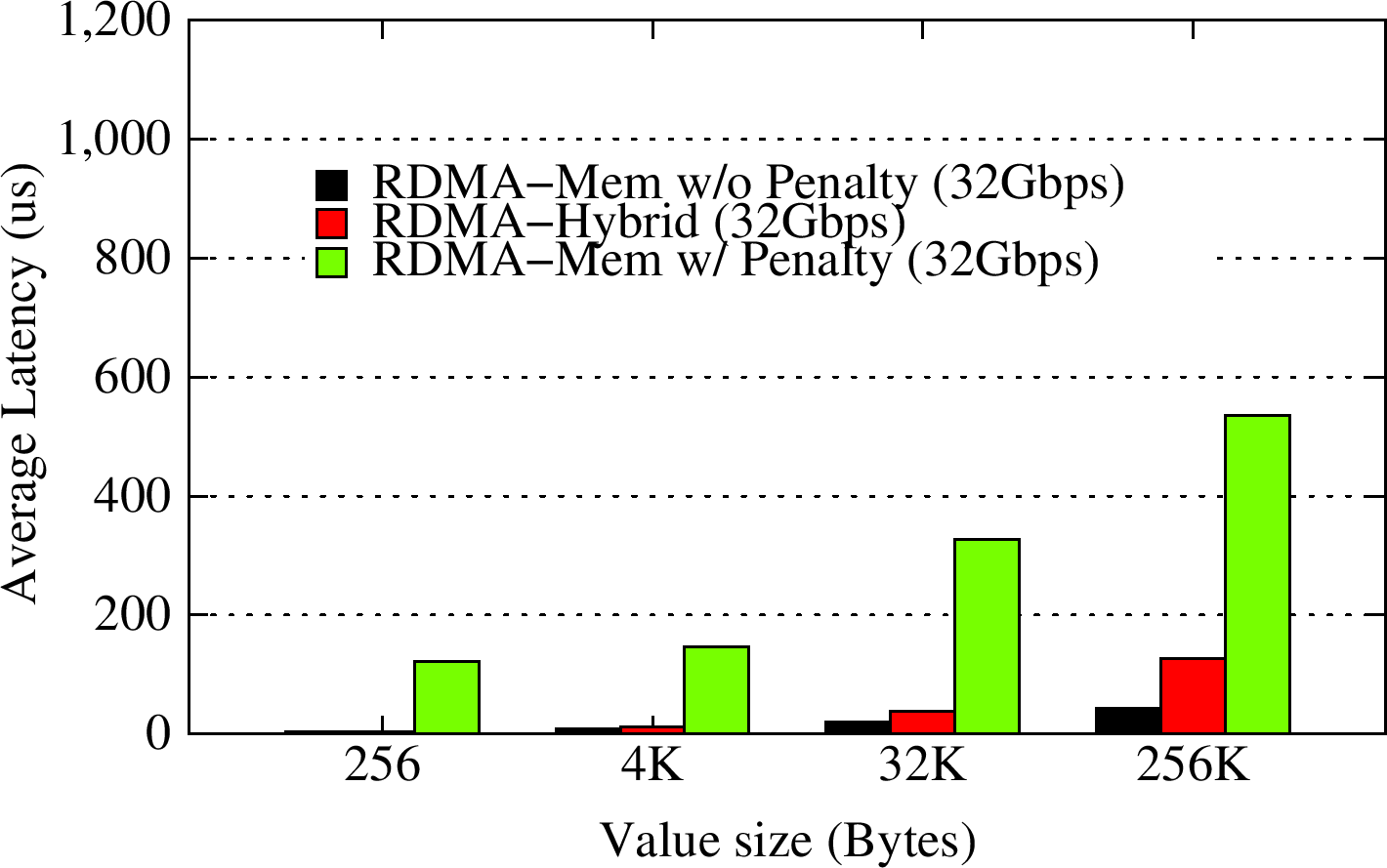
In the OHB Hybrid Micro-benchmark with Zipfian distribution pattern, the Memcached client attempts to over-flow the Memcached server for a particular message size (spill factor of 1.5 i.e., workload size = 1.5 * memcached server memory), and then reads the key/value pairs at using a Zipf distribution. We modify the benchmark to query the least-recently updated (Earliest) and most-recently updated (Latest) key-value pairs. We vary the miss penalty from 0.5 ms to 1.5 ms for different value sizes. The RDMA-enhanced SSD-based Hybrid Memcached design improves the latency of gets by up to 10x for small key-value pair sizes for success rates as low as 15% over pure In-memory RDMA-enhanced Memcached with a Memcached server miss penalty, and up to 5x for larger key-value pair sizes for low success rates.
In the OHB Hybrid Micro-benchmark with Uniform Pattern, the Memcached client attempts to over-flow the Memcached server for a particular message size (spill factor of 1.5), and then reads the key/value pairs uniformly at random. We vary the miss penalty from 0.5 ms to 1.5 ms for smaller to larger value sizes. The RDMA-enhanced SSD-based Hybrid Memcached design improves the latency of gets by more than 5x improvement over pure In-memory RDMA-enhanced Memcached with a miss penalty, with a success rate of around 25%.
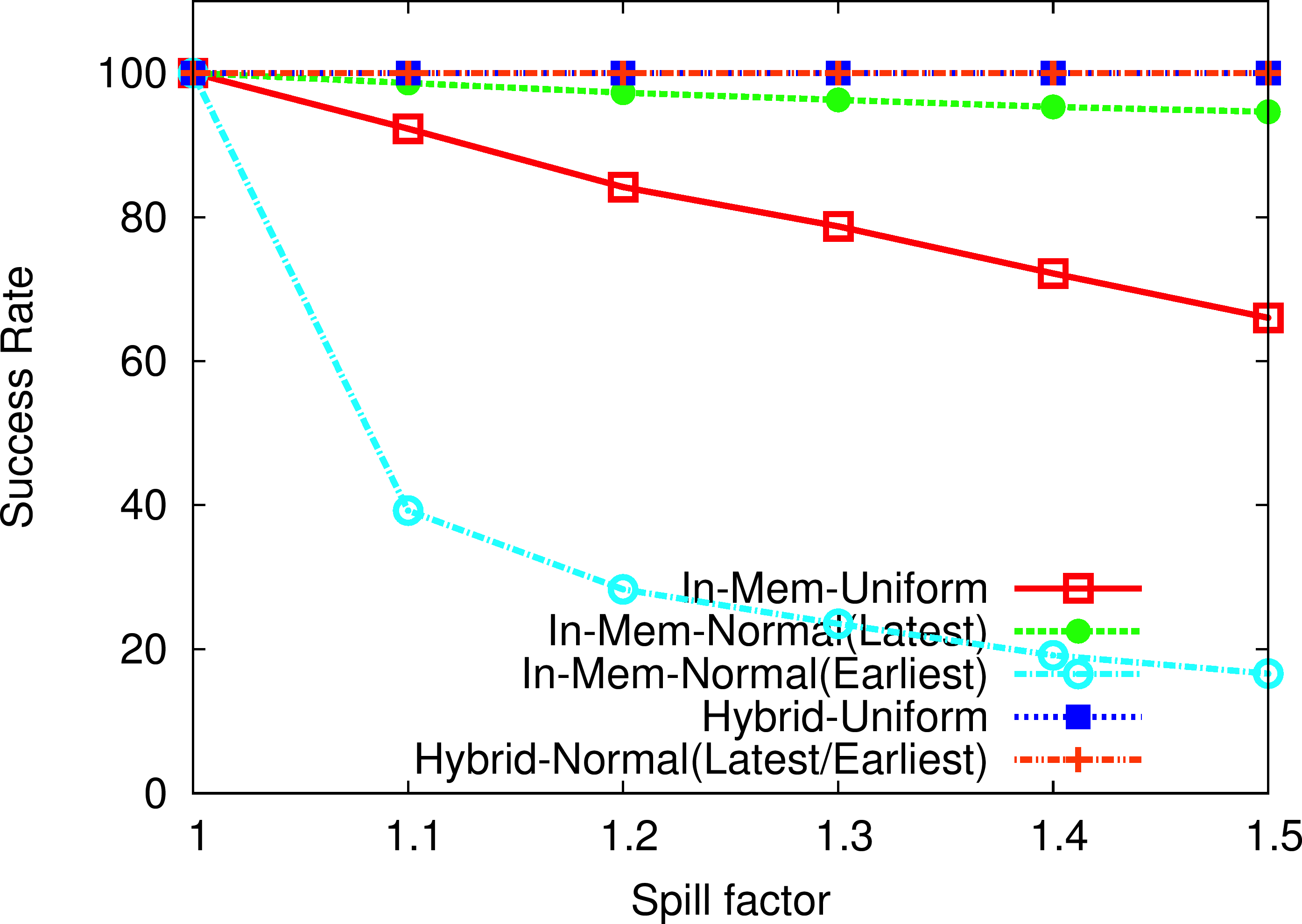
In the OHB Hybrid Micro-benchmark Success Rate test, the Memcached client attempts to over-flow the Memcached server for a particular message size, and measure the success rate as the number of key/value pairs successfully fetched versus number of get attempts made, for different spill factors. As the RDMA-enhanced SSD-based Hybrid Memcached design faciliatates us to hold more key/values pairs, as compared to pure In-memory RDMA-enhanced Memcached, the success rate with the hybrid design remains constant at 100% while that of pure in-memory design degrades.
OHB Non-Blocking Set Micro-benchmark
OHB Non-Blocking Get Micro-benchmark
Experimental Testbed (OSU - RI2 Cluster): Each storage node on OSU-RI2 has two fourteen Core Xeon E5-2680v4 processors at 2.4 GHz, 512 GB main memory, and a single 400GB PCIe SSD. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
These experiments are performed with a single Memcached server running with up to 64GB of memory in SSD-Assisted Hybrid mode and a single Memcached client node.
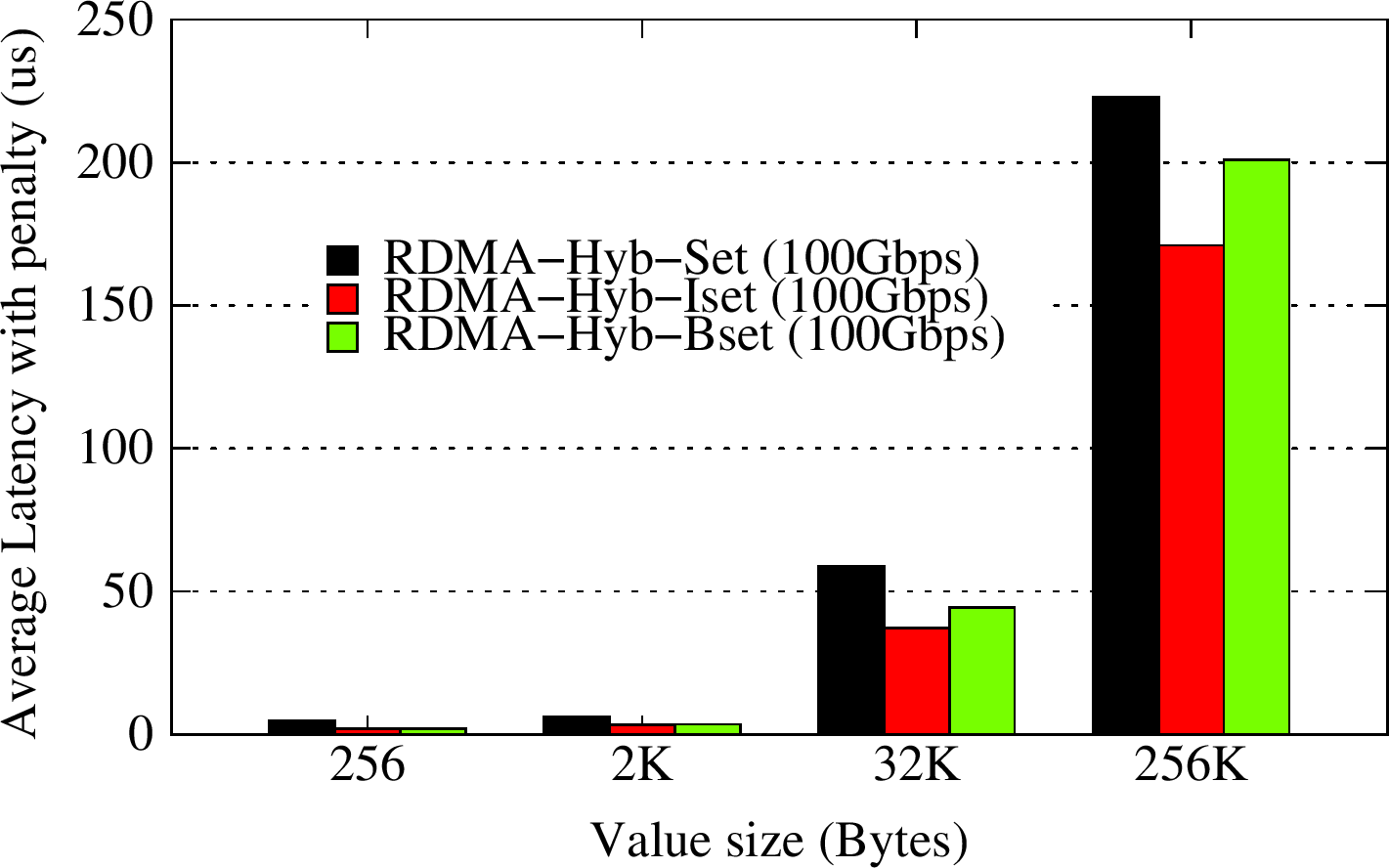
In the OHB Non-Blocking Set Micro-benchmark, the Memcached client issues set requests using memcached_iset and memcached_bset APIs and monitors them asynchronously using memcached_test or memcached_wait progress APIs with a request threshold of 32 ongoing requests. For varying key/value pair sizes, the iset/bset RDMA-enabled non-blocking APIs can improve overall set latency by 15-57% over the default blocking set API while using the RDMA-enhanced Memcached design.
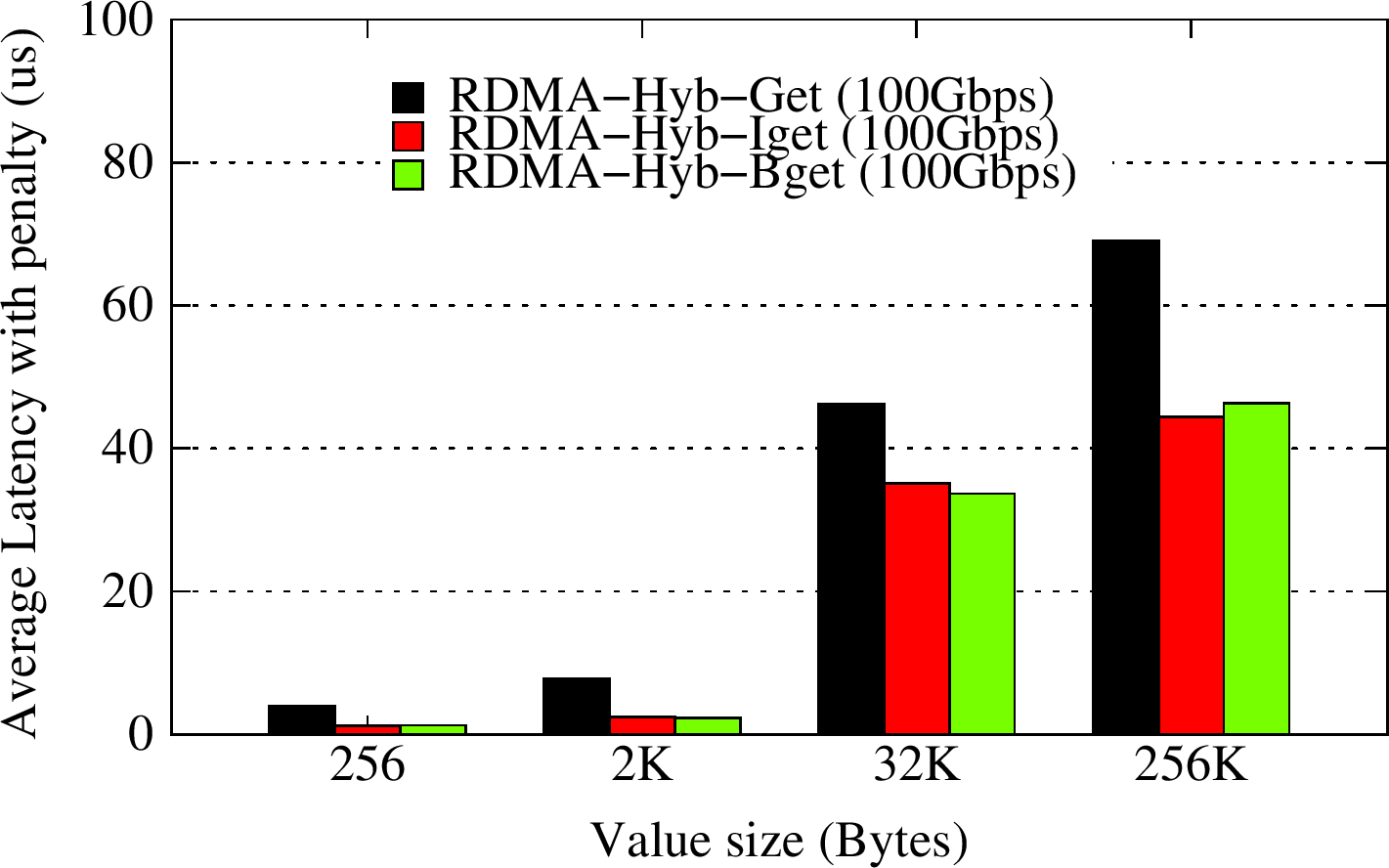
In the OHB Non-Blocking Get Micro-benchmark, the Memcached client issues get requests using memcached_iget and memcached_bget APIs and monitors them asynchronously using memcached_test or memcached_wait progress APIs with a request threshold of 32 ongoing requests. For varying key/value pair sizes, the iget/bget RDMA-enabled non-blocking APIs can improve overall get latency by over 36%-65% over the default blocking get API while using the RDMA-enhanced Memcached design.
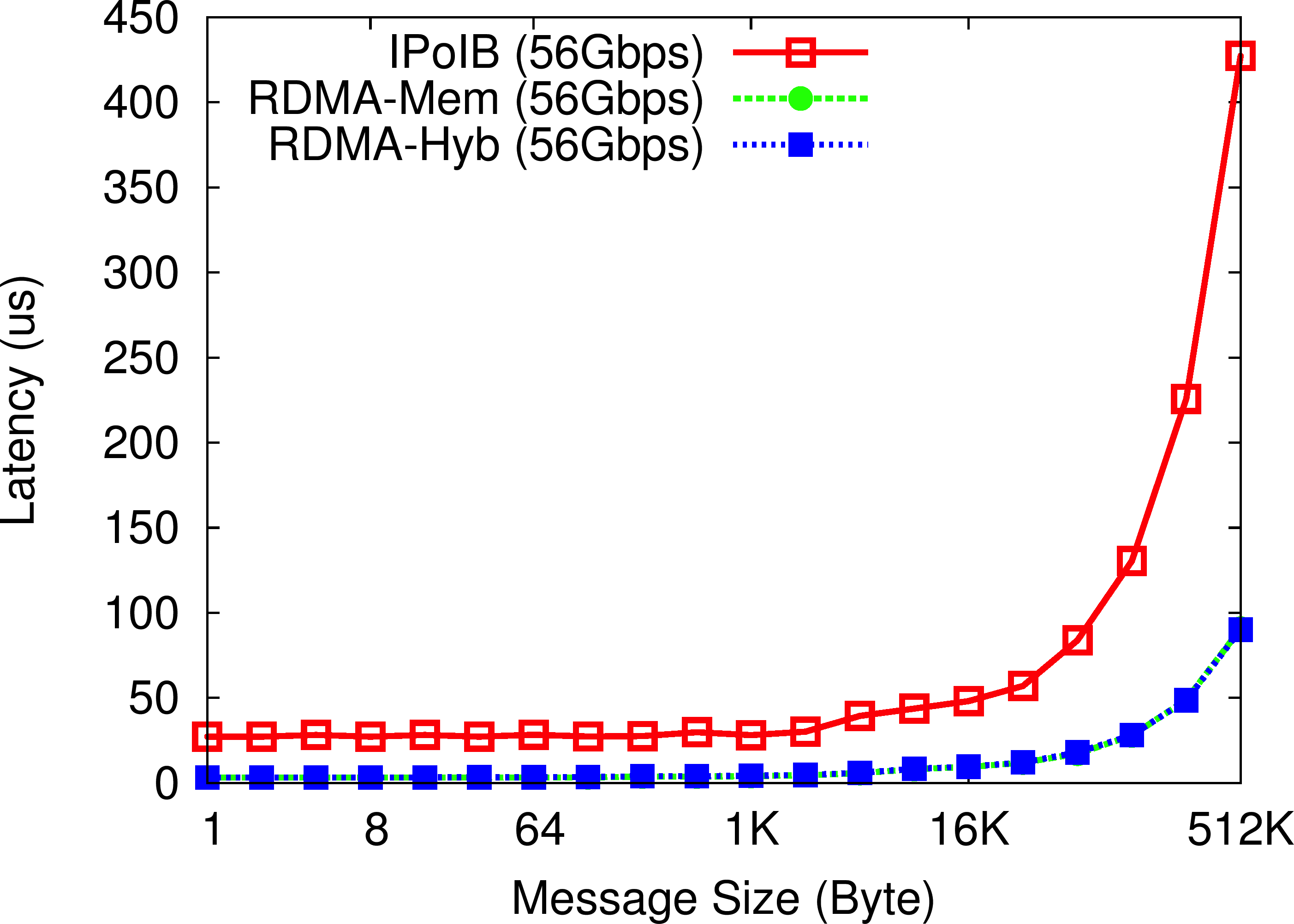
OHB Set Micro-benchmark
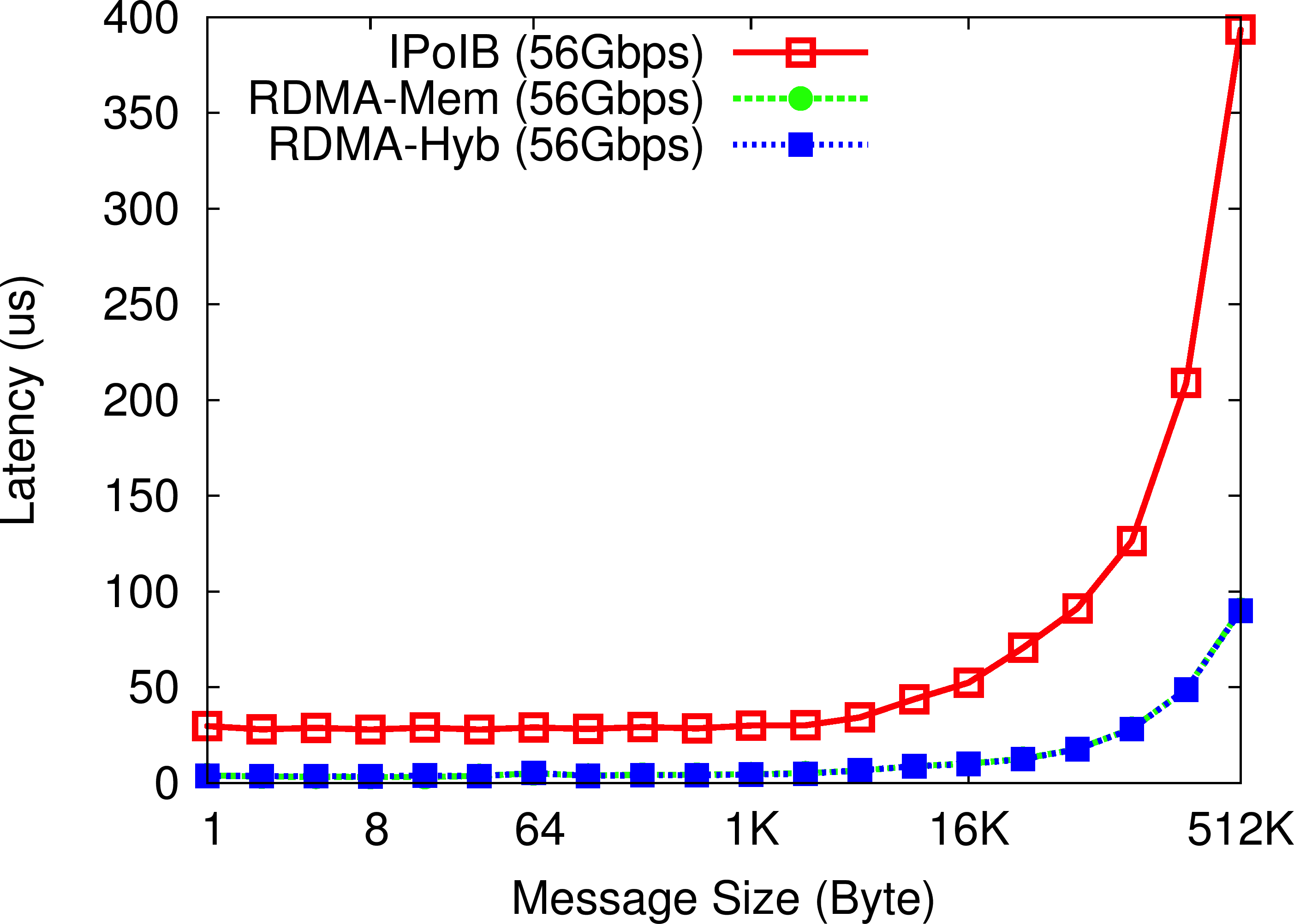
OHB Get Micro-benchmark
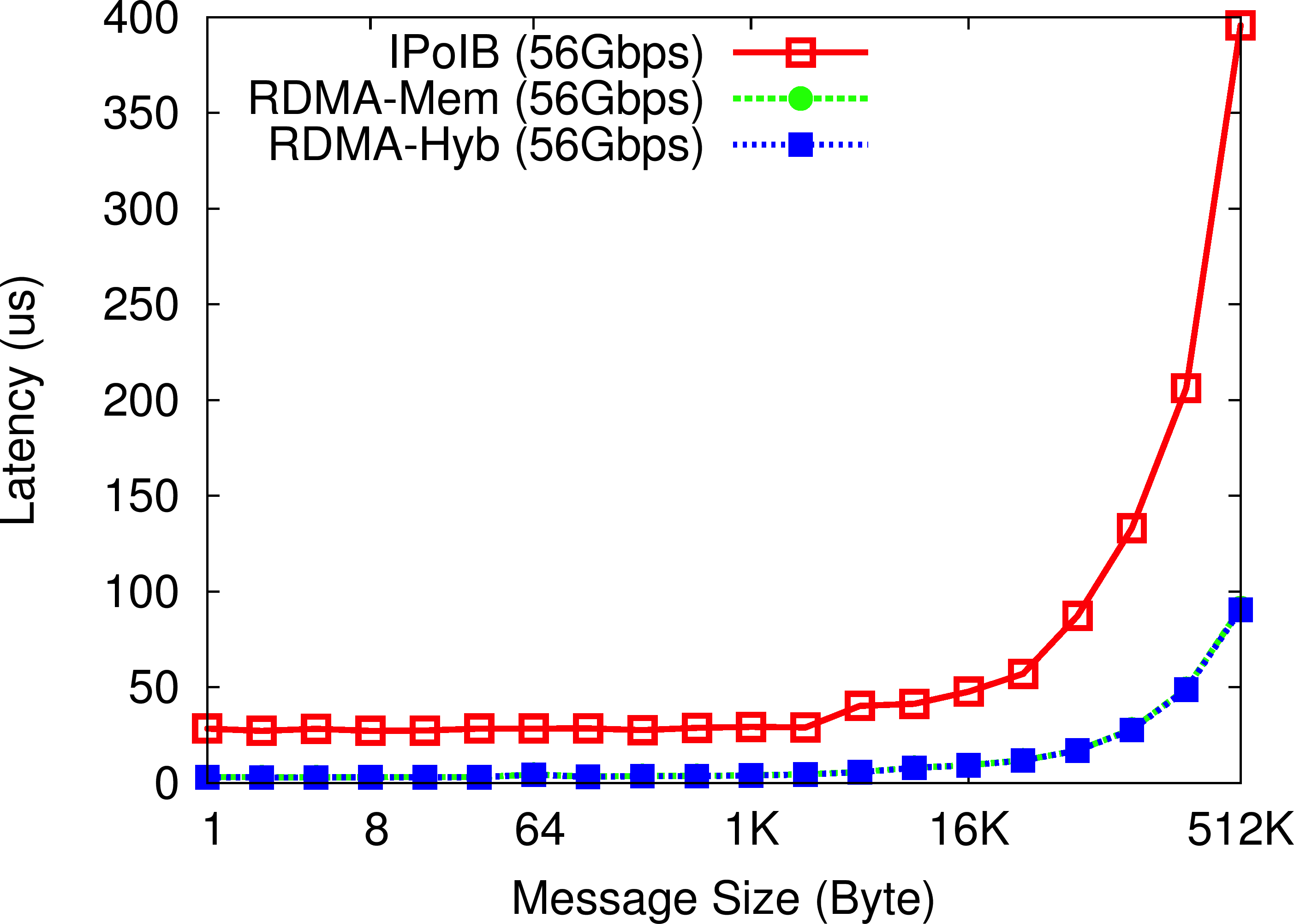
OHB Mix Micro-benchmark
Experimental Testbed (SDSC - Comet): Each compute node in this cluster has two twelve-core Intel Xeon E5-2680 v3 (Haswell) processors, 128GB DDR4 DRAM, and 320GB of local SATA-SSD with CentOS operating system. The network topology in this cluster is 56Gbps FDR InfiniBand with rack-level full bisection bandwidth and 4:1 over-subscription cross-rack bandwidth.
These experiments are performed with a single Memcached server running with 16 GB of memory and a single Memcached client node.
In the OHB Set Micro-benchmark, the Memcached client repeatedly sets an item of a particular size on the Memcached server. The RDMA-enhanced Memcached design (both In-memory and SSD-based Hybrid) improves the latency of set operations by up to 70% over default Memcached running over IPoIB (56Gbps).
In the OHB Get Micro-benchmark, the Memcached client repeatedly gets an item of a particular size from the Memcached server. Compared to IPoIB (56Gbps), the RDMA-enhanced Memcached design (both In-memory and SSD-based Hybrid) improves the latency of get operations by up to 69%.
In the OHB Mix Micro-benchmark, the Memcached client repeatedly sets and gets an item of a particular size on the Memcached server, with a read/write mix of 90/10. We can observe that the RDMA-enhanced Memcached design (both In-memory and SSD-based Hybrid) improves the latency of set operations by up to 71% as compared to default Memcached over IPoIB (56Gbps).
Dept of Computer Science and Engineering
2001-2025 NBCL. All rights reserved.


2015 Neil Avenue
Columbus, OH 43210