

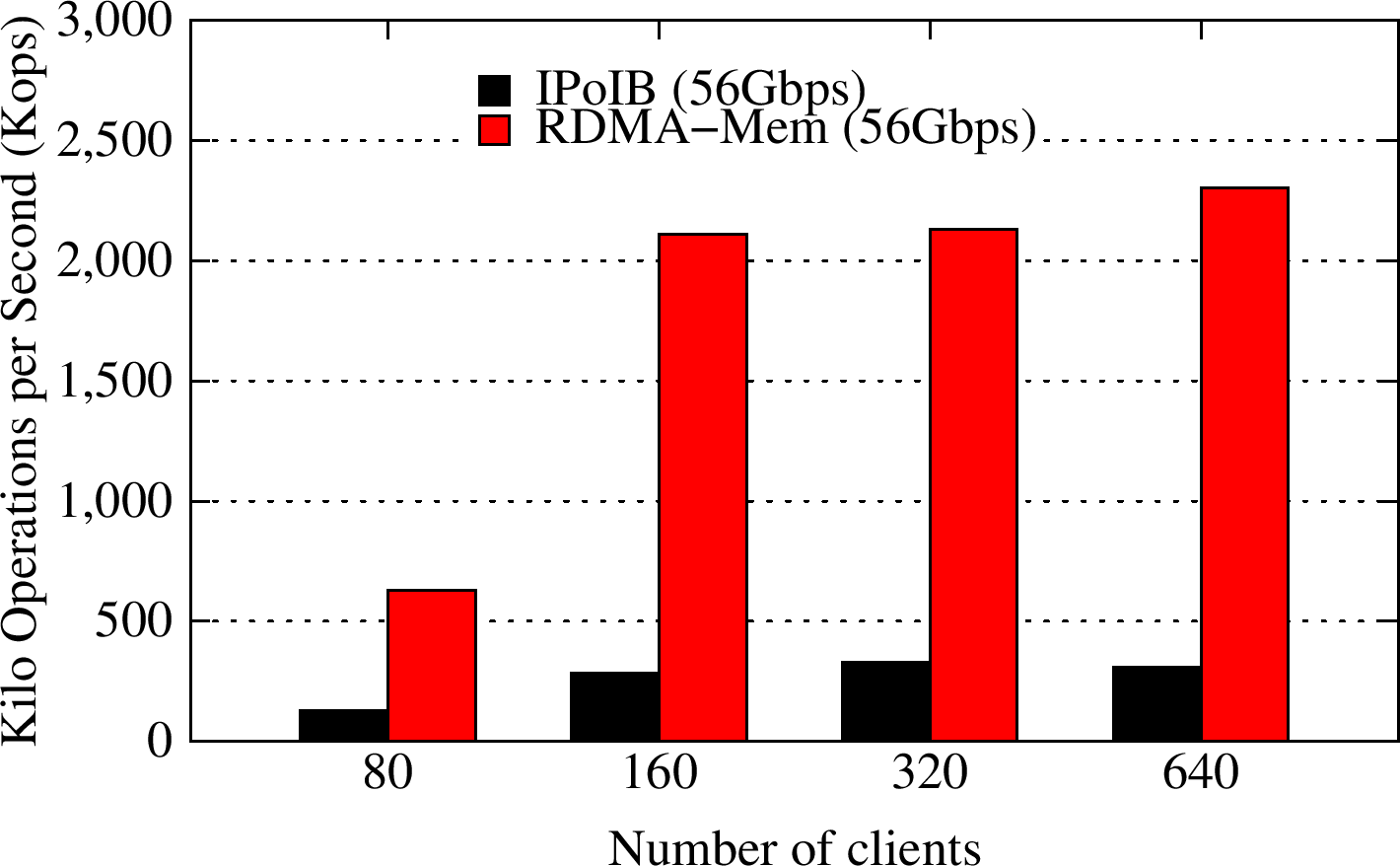
YCSB A
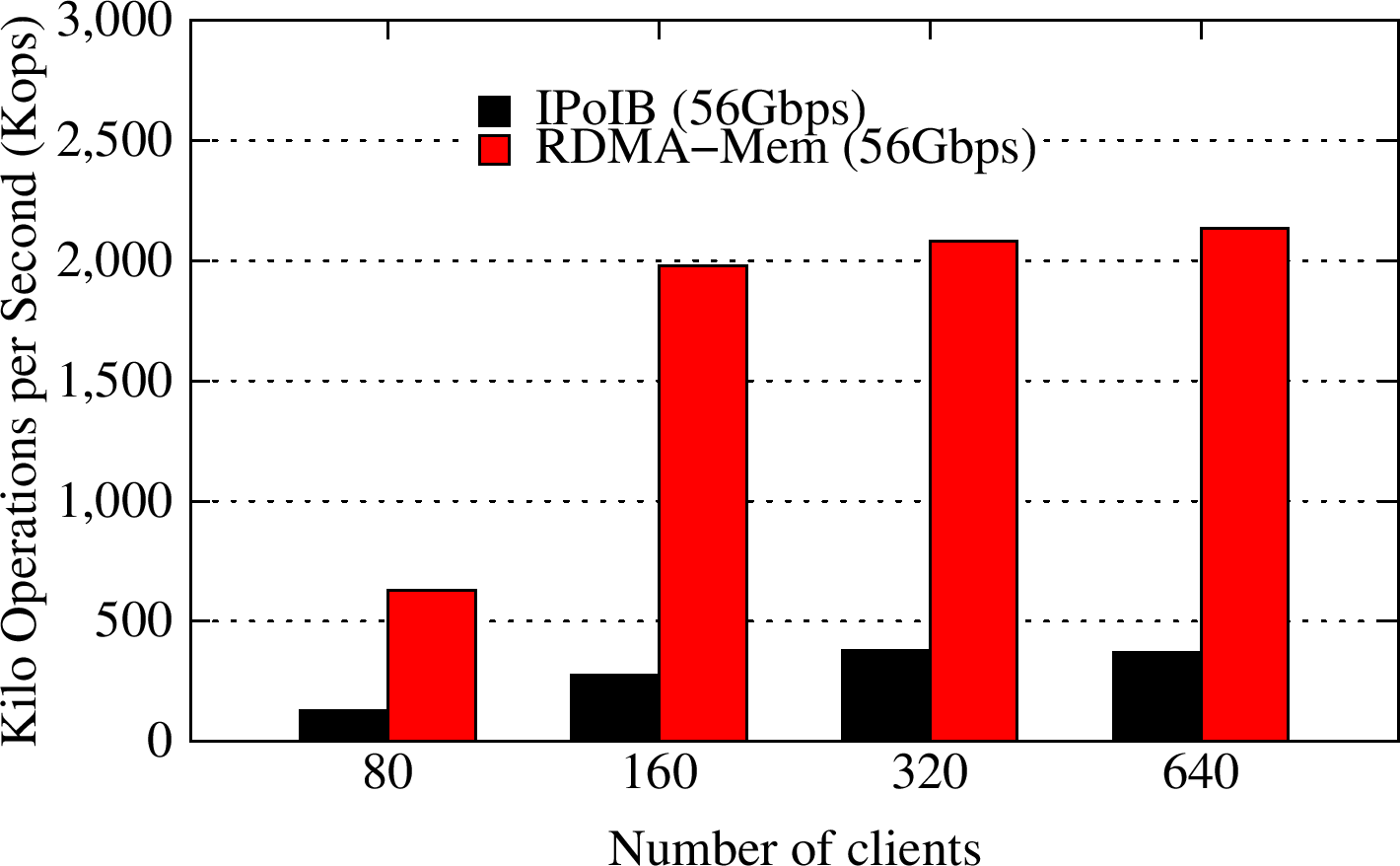
YCSB B
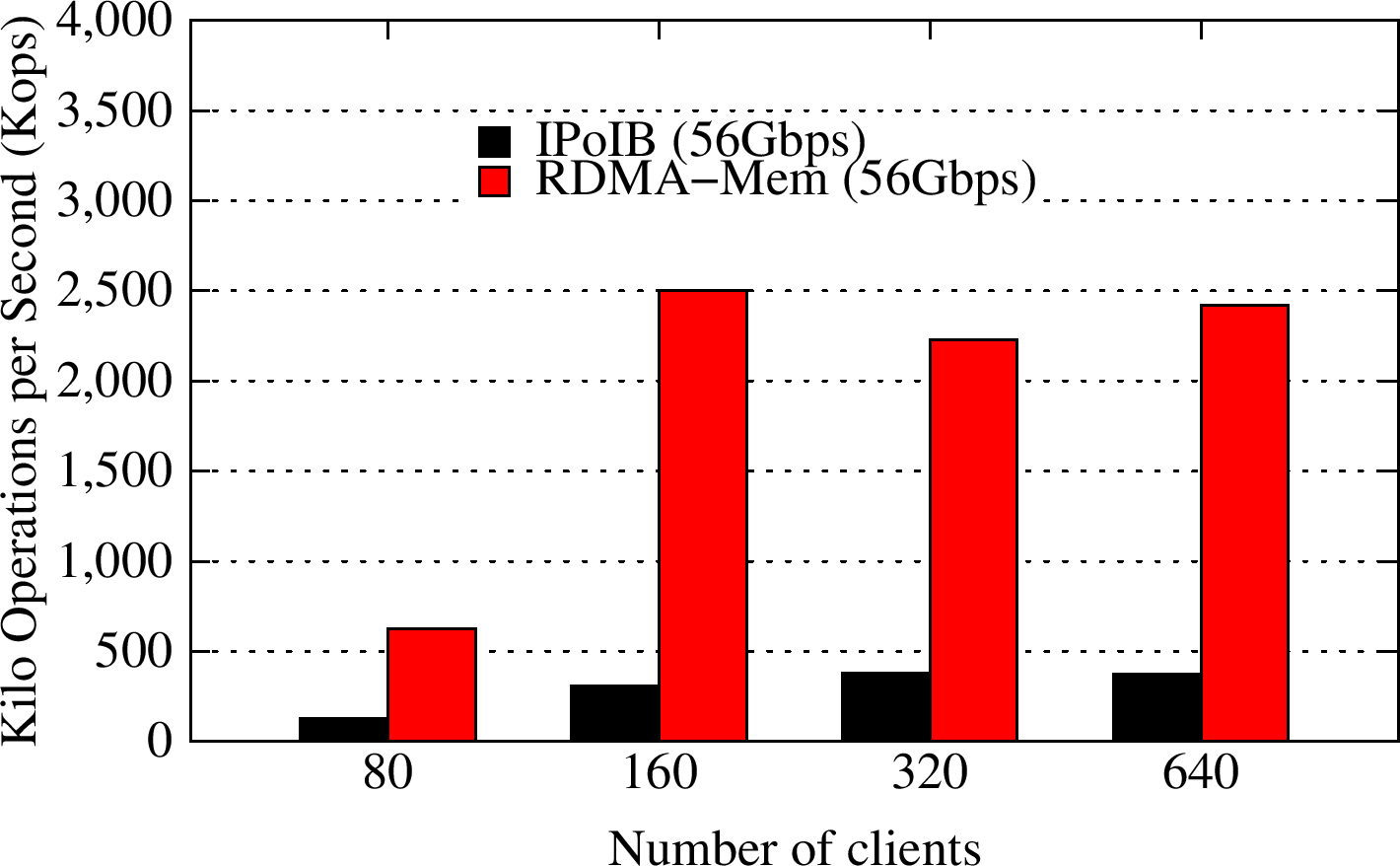
YCSB C
Experimental Testbed (SDSC - Comet): Each compute node in this cluster has two twelve-core Intel Xeon E5-2680 v3 (Haswell) processors, 128GB DDR4 DRAM, and 320GB of local SATA-SSD with CentOS operating system. The network topology in this cluster is 56Gbps FDR InfiniBand with rack-level full bisection bandwidth and 4:1 over-subscription cross-rack bandwidth.
These experiments are performed with 3-node Memcached server cluster with 64 GB memory per node and up to 32 compute nodes for running Memcached clients. We run these benchmarks with extended YCSB benchmark suite for RDMA-Memcached, available as a part of OSU HiBD benchmarks v0.9.3. We run YCSB with 80 to 640 clients.
YCSB workload A has a 50:50 read:update pattern. The RDMA-enhanced Memcached design improves the overall throughput for this Update-Heavy workload by about 6.7X, as compared to default Memcached running over IPoIB (56Gbps).
YCSB workload B runs a 95:5 read:update pattern. The RDMA-enhanced Memcached design improves the overall throughput for this Read-Heavy workload by about 5.7X, as compared to default Memcached running over IPoIB (56Gbps).
YCSB workload C runs a 56:0 read:update pattern. The RDMA-enhanced Memcached design improves the overall throughput for this Read-Only workload by about 6.4X, as compared to default Memcached running over IPoIB (56Gbps).
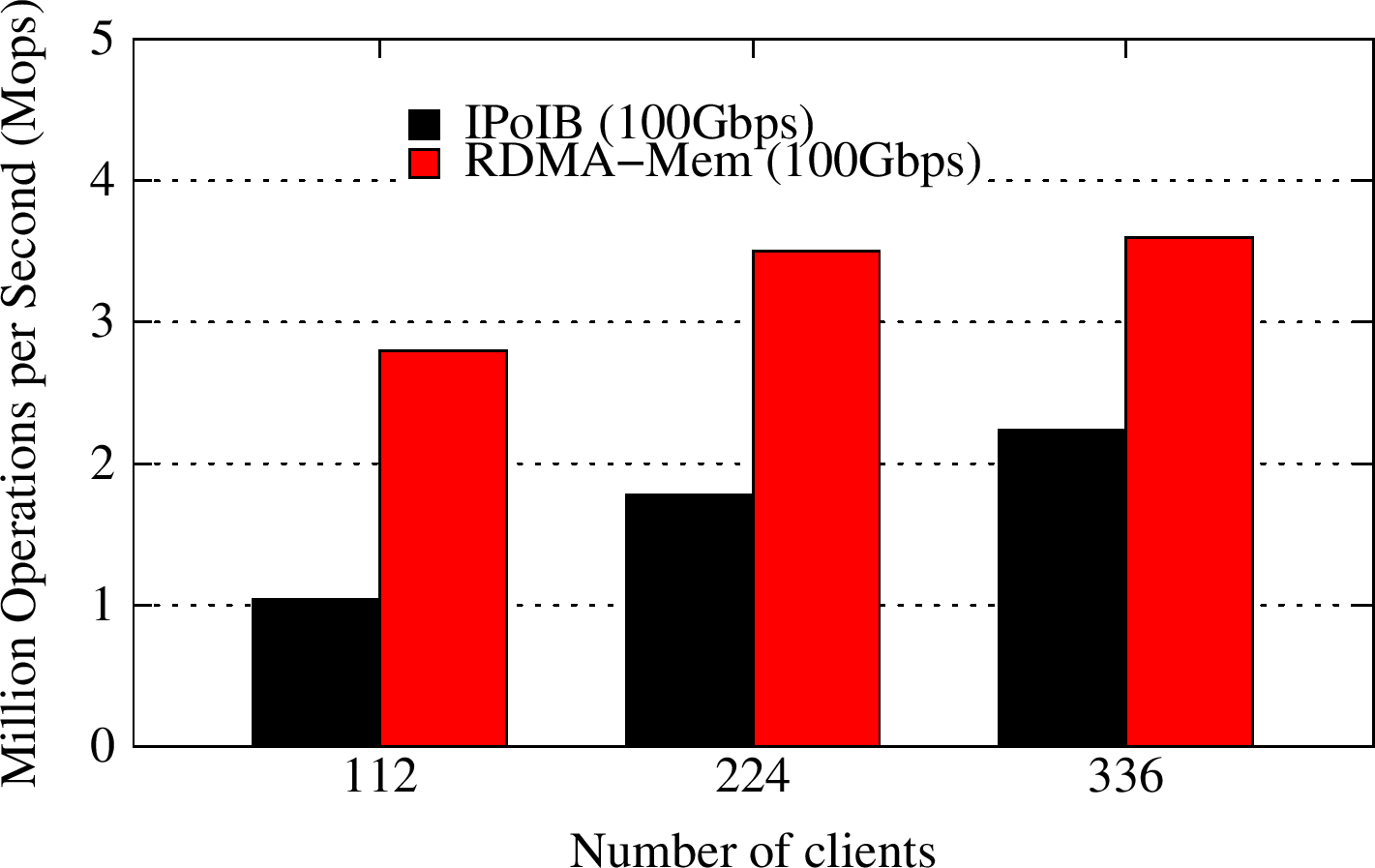
YCSB A
YCSB B
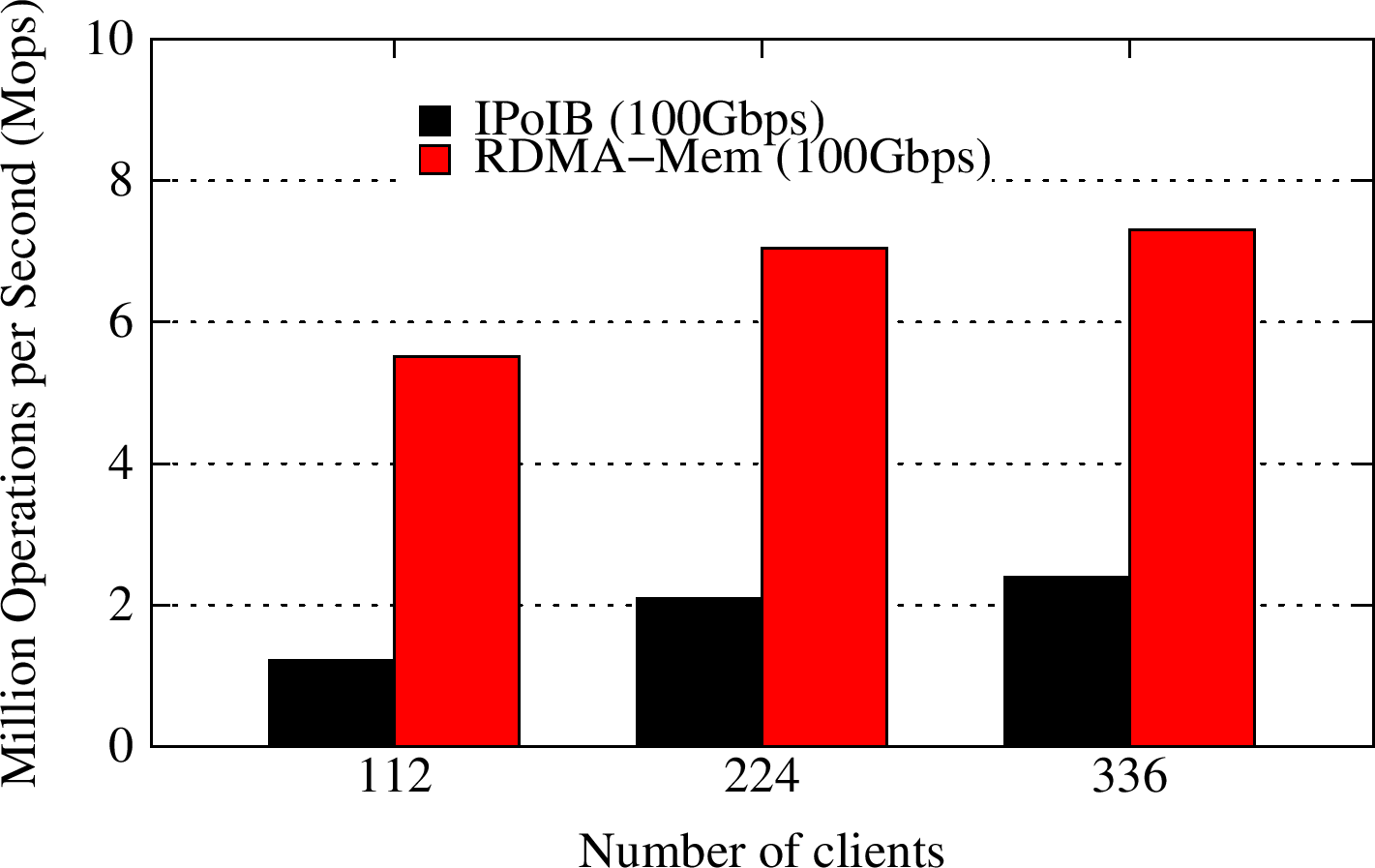
YCSB C
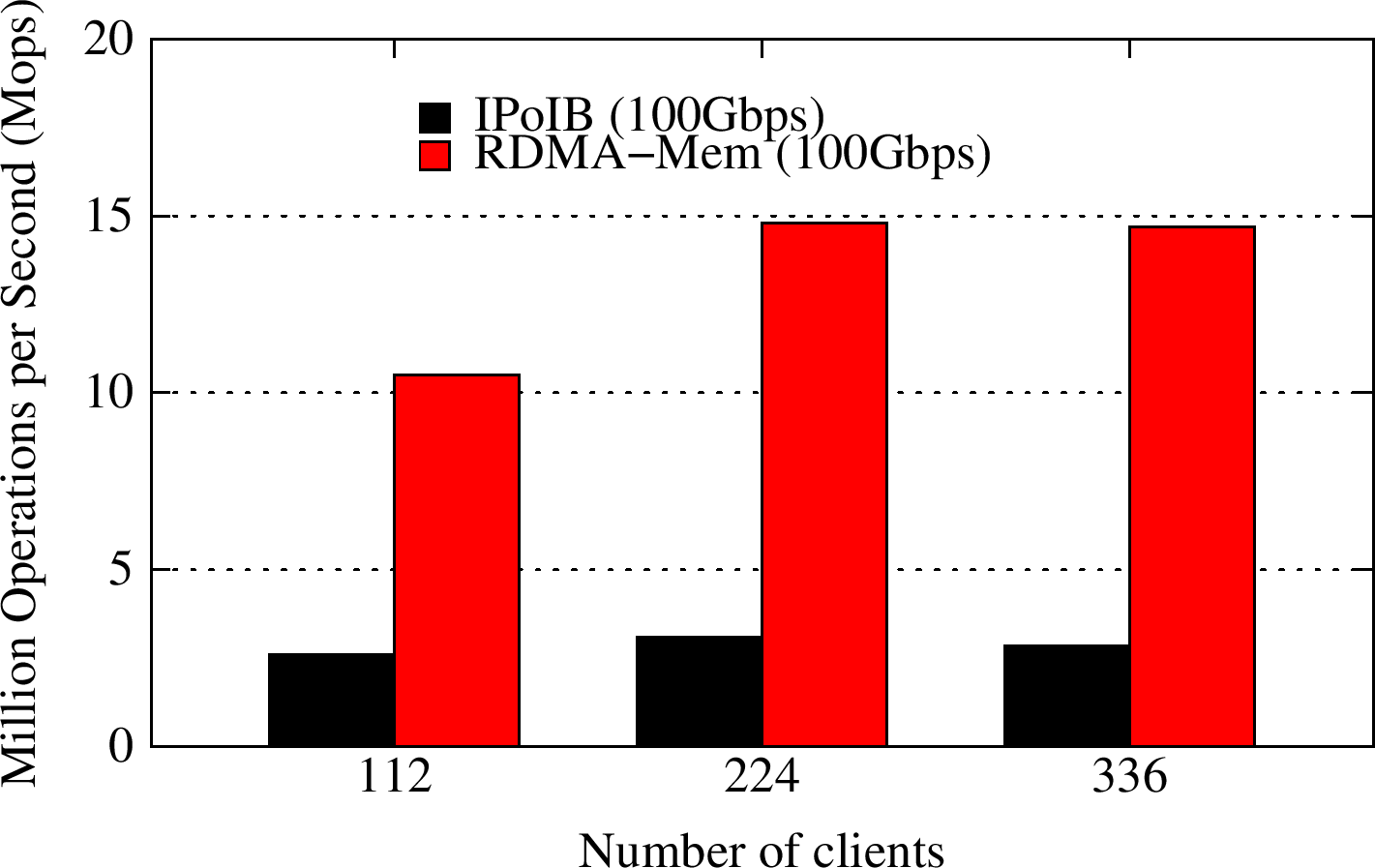
Experimental Testbed (OSU - RI2 Cluster): Each compute node on OSU-RI2 has two fourteen Core Xeon E5-2680v4 processors at 2.4 GHz and 128 GB main memory. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
These experiments are performed with 3-node Memcached server cluster with 72 GB memory per node and up to 12 compute nodes for running Memcached clients. We run these benchmarks with extended YCSB benchmark suite for RDMA-Memcached, available as a part of OSU HiBD benchmarks v0.9.3. We run YCSB with 112 to 336 clients.
YCSB workload A has a 50:50 read:update pattern. The RDMA-enhanced Memcached design improves the overall throughput for this Update-Heavy workload by about 1.7X, as compared to default Memcached running over IPoIB (100Gbps).
YCSB workload B runs a 95:5 read:update pattern. The RDMA-enhanced Memcached design improves the overall throughput for this Read-Heavy workload by about 3.53X, as compared to default Memcached running over IPoIB (100Gbps).
YCSB workload C runs a 100:0 read:update pattern. The RDMA-enhanced Memcached design improves the overall throughput for this Read-Only workload by about 4.64X, as compared to default Memcached running over IPoIB (100Gbps).
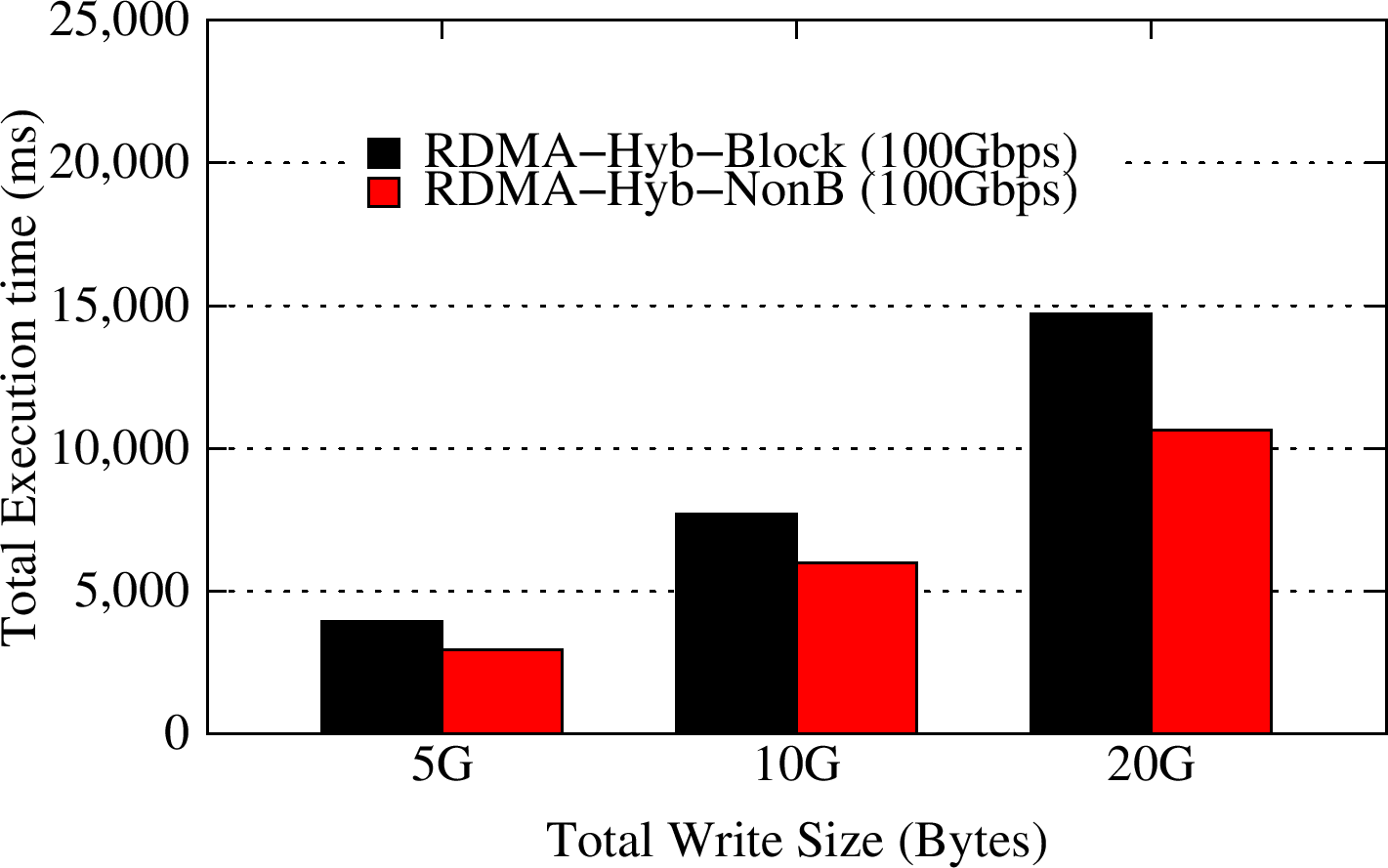
Total Write Time Per Client: 512 MB chunks
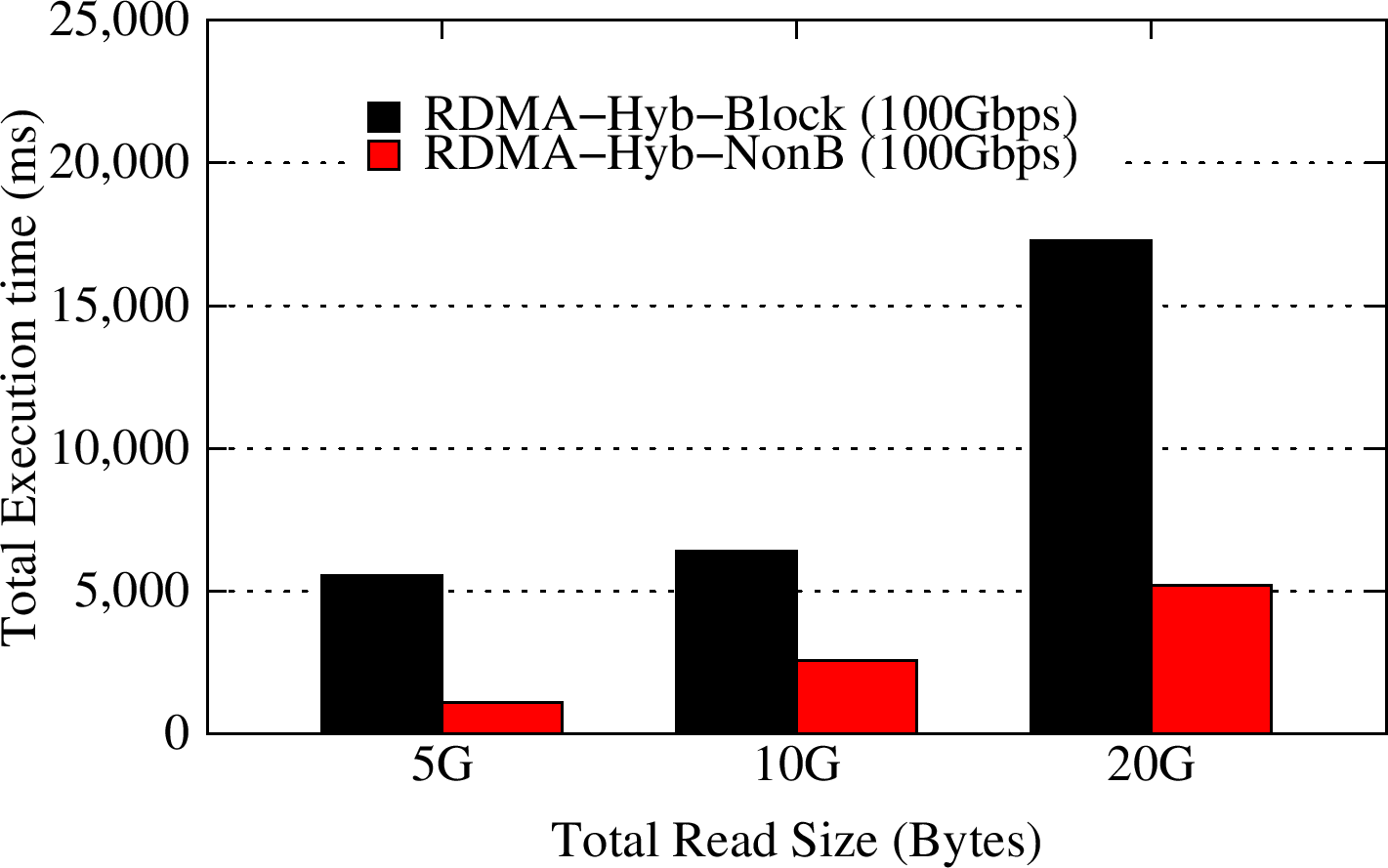
Total Read Time Per Client: 512 MB chunks
Experimental Testbed (OSU - RI2 Cluster): Each storage node is provisioned with Intel Broadwell (E5-2680-v4) dual fourteen-core processors, 512 GB of memory and a Mellanox IB EDR HCA. These experiments are performed with 4 Memcached servers and up to 16 clients instances.
This multi-client test is an extension of the I/O pattern example with non-blocking APIs that is provided with the libmemcached library withtin the RDMA for Memcached package version 0.9.5. All the clients start by setting keys that represnt data blocks to the Memcached servers and then access these data blocks in order. This scalability test simulates the case where multiple clients access the Memcached servers simultaneously with total data stored and accessed varying from 5GB to 20GB. We use key/value pair sizes of 512 MB. The non-blocking API extensions with the RDMA-enhanced design can achieve an improvement of 1.25-2.25X over blocking APIs for write phase and an improvement of 2.51-4.97X over blocking APIs with RDMA-based designs for the read phase.

