

This benchmark creates a cuPy array and distributes its chunks across Dask workers. The benchmark adds these distributed chunks to their transpose, forcing the GPU data to move around over the network. We compare the performance of MVAPICH2-GDR based communication device in the Dask Distributed library, MPI4Dask here, with UCX and TCP (using IPoIB) communication devices on an in-house cluster called RI2.
Sum of cuPy Array and Transpose Execution Time and Average Worker Throughput
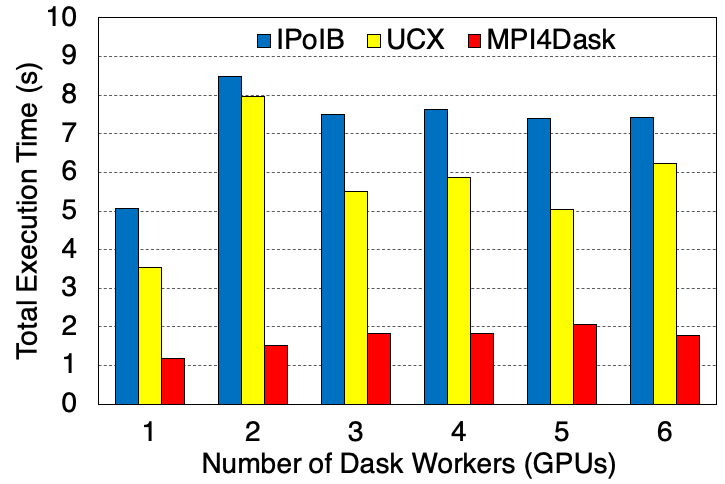
Execution Time
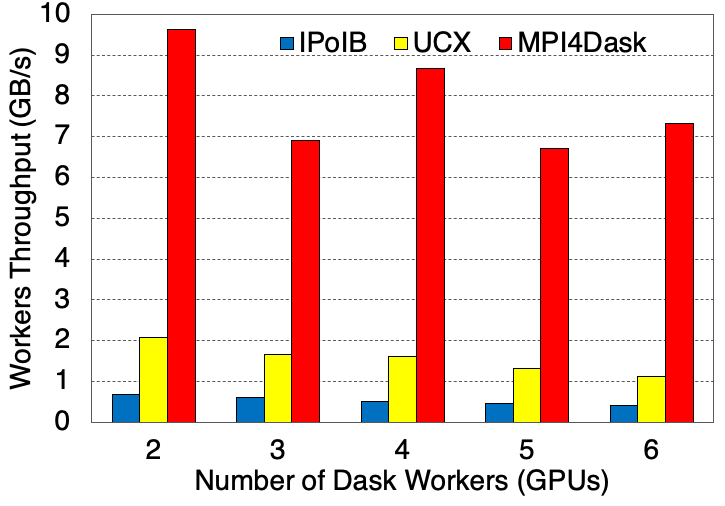
Average Worker Throughput
Experimental Testbed: Each node in OSU-RI2 has two fourteen core Xeon E5-2680v4 processors at 2.4 GHz and 512 GB main memory. Each node has 1 NVIDIA V100 GPU with 32GB memory. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
The cuPy array dimensions are 16E4x16E4 and the chunk size is 4E4. There are total 16 partitions. The benchmark is presenting strong scaling results. 28 threads are started for each Dask worker.
Sum of cuPy Array and Transpose Execution Time

Experimental Testbed: This system has 90 nodes. Each compute node in this cluster has two sixteen-core Intel Xeon E5-2620 v4 processors, 128GB DDR4 DRAM with 4 NVIDIA Quadro RTX 5000 GPUs with 16 GB memory. The interconnect in this cluster is 56Gbps FDR InfiniBand.
The cuPy array dimensions are 20E3x20E3 and the chunk size is 5E2. The benchmark is presenting strong scaling results. 8 threads are started for each Dask worker.

