

cuDF DataFrames are table-like data-structure that are stored in the GPU memory. As part of this application, merge operation is carried out for multiple cuDF data frames. We compare the performance of MVAPICH2-GDR based communication device in the Dask Distributed library, MPI4Dask here, with UCX and TCP (using IPoIB) communication devices on an in-house cluster called RI2.
cuDF Merge Operation Execution Time and Average Worker Throughput
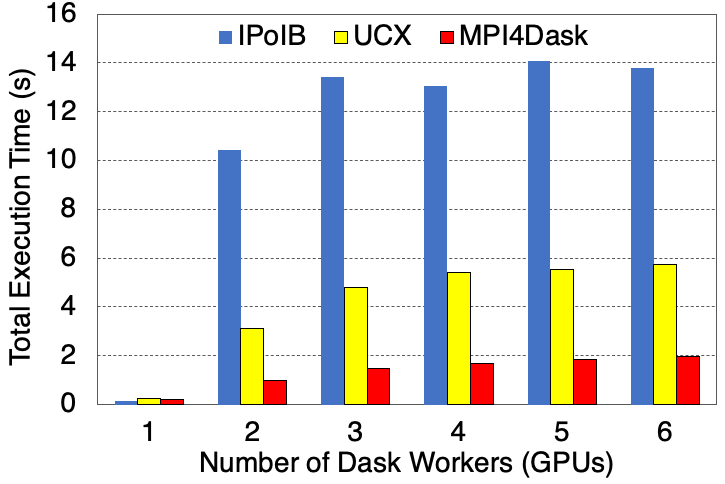
Execution Time
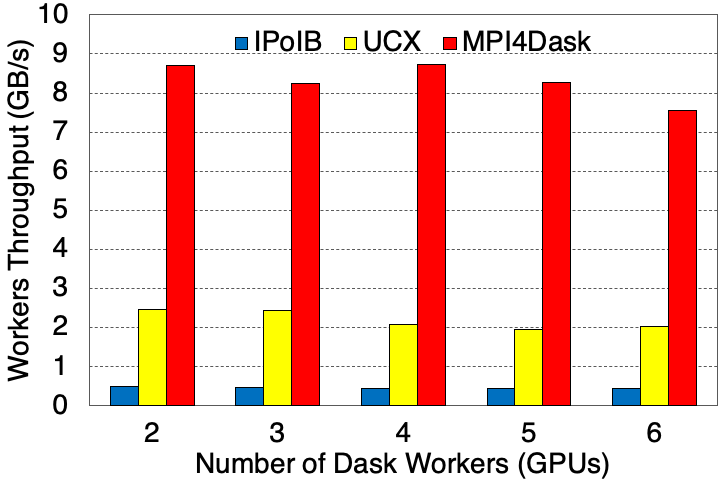
Average Worker Throughput
Experimental Testbed: Each node in OSU-RI2 has two fourteen core Xeon E5-2680v4 processors at 2.4 GHz and 512 GB main memory. Each node has 1 NVIDIA V100 GPU with 32GB memory. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
The chunksize for the cuDF structures is 1E8 and the shuffle flag has been turned on. This benchmark presents weak scaling results. 28 threads are started in a single Dask worker. 3.2 GB of data is processed per Dask worker (or GPU).
cuDF Merge Operation Execution Time and Application Throughput
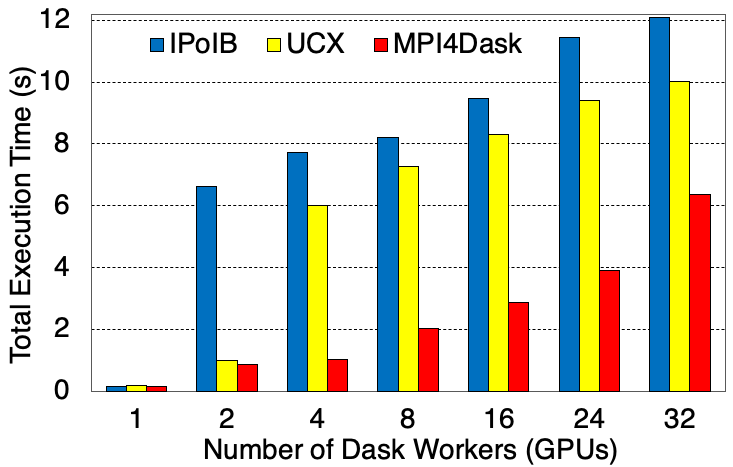
Execution Time
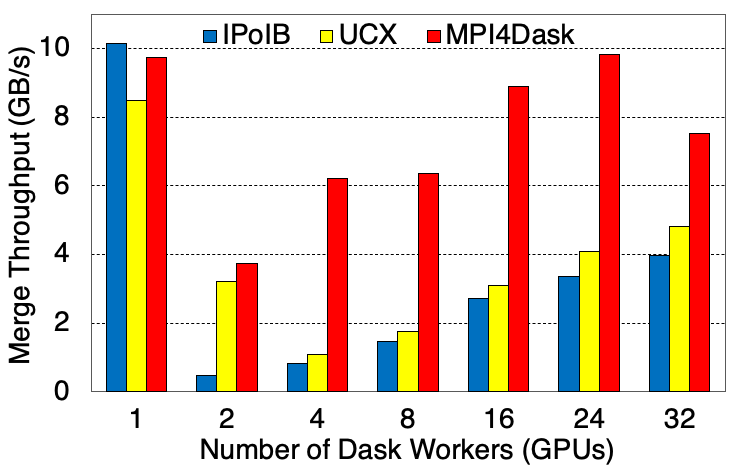
Application Throughput
Experimental Testbed: This system has 90 nodes. Each compute node in this cluster has two sixteen-core Intel Xeon E5-2620 v4 processors, 128GB DDR4 DRAM with 4 NVIDIA Quadro RTX 5000 GPUs with 16 GB memory. The interconnect in this cluster is 56Gbps FDR InfiniBand.
The chunksize for the cuDF structures is 5E7 and the shuffle flag has been turned on. This benchmark presents weak scaling results. There are 4 GPUs in a single node and 1 Dask worker is started per GPU. 8 threads are started in a single Dask worker. 1.6 GB of data is processed per Dask worker (or GPU).

