

This benchmark evaluates the performance of inter-node point-to-point asynchronous communication co-routines provided by MPI4Dask and UCX-Py. This evaluation is done separately for inter-node GPU-to-GPU and CPU-to-CPU scenarios. For both cases, we present latency and bandwidth comparisons. We compare performance of MPI4Dask and UCX-Py communication co-routines against the baseline MVAPICH2 and UCX communication routines. This evaluation was done on an in-house cluster called RI2.
Latency/Bandwidth Evaluation using the Ping-pong Benchmark
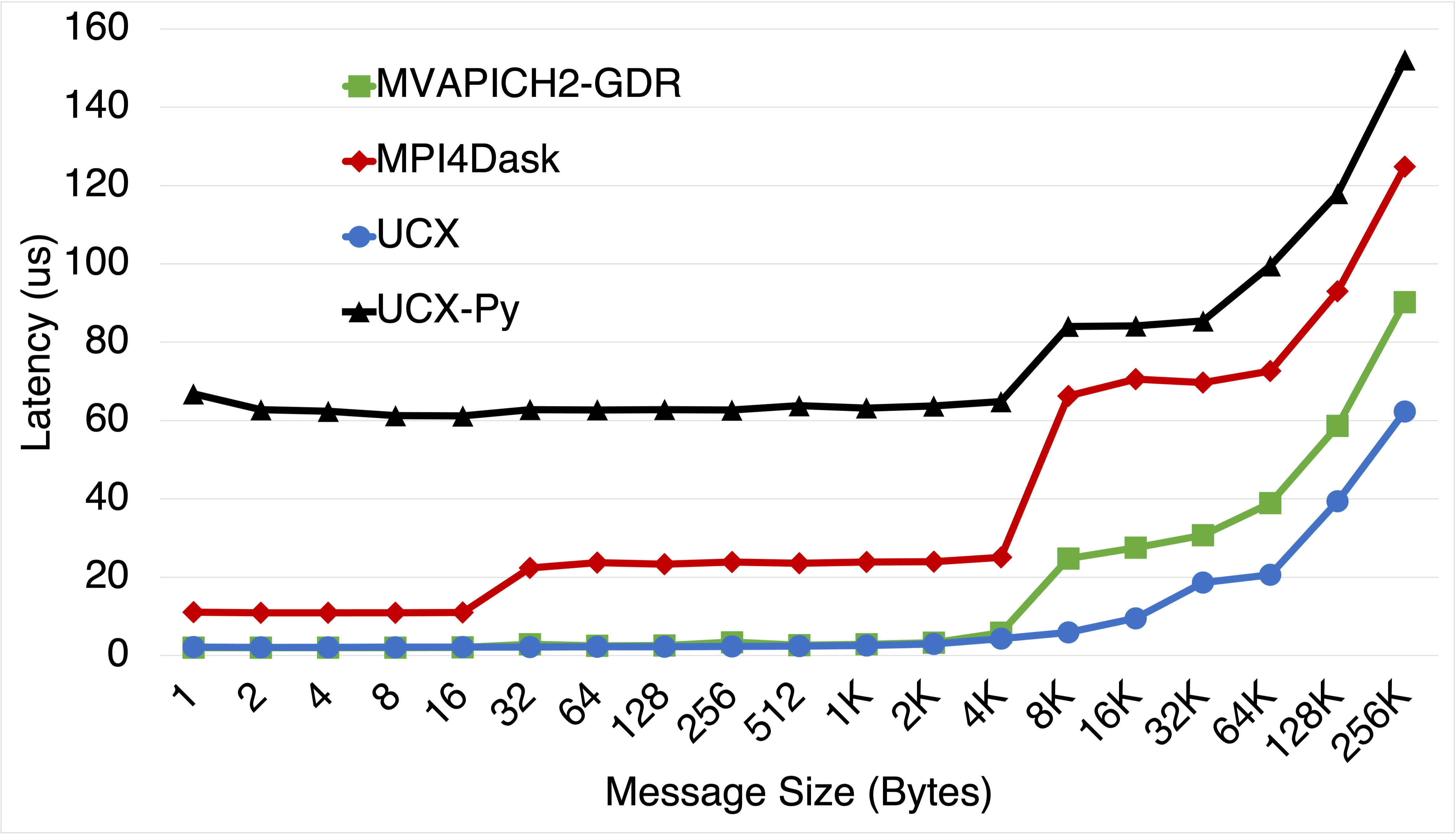
Latency Comparison
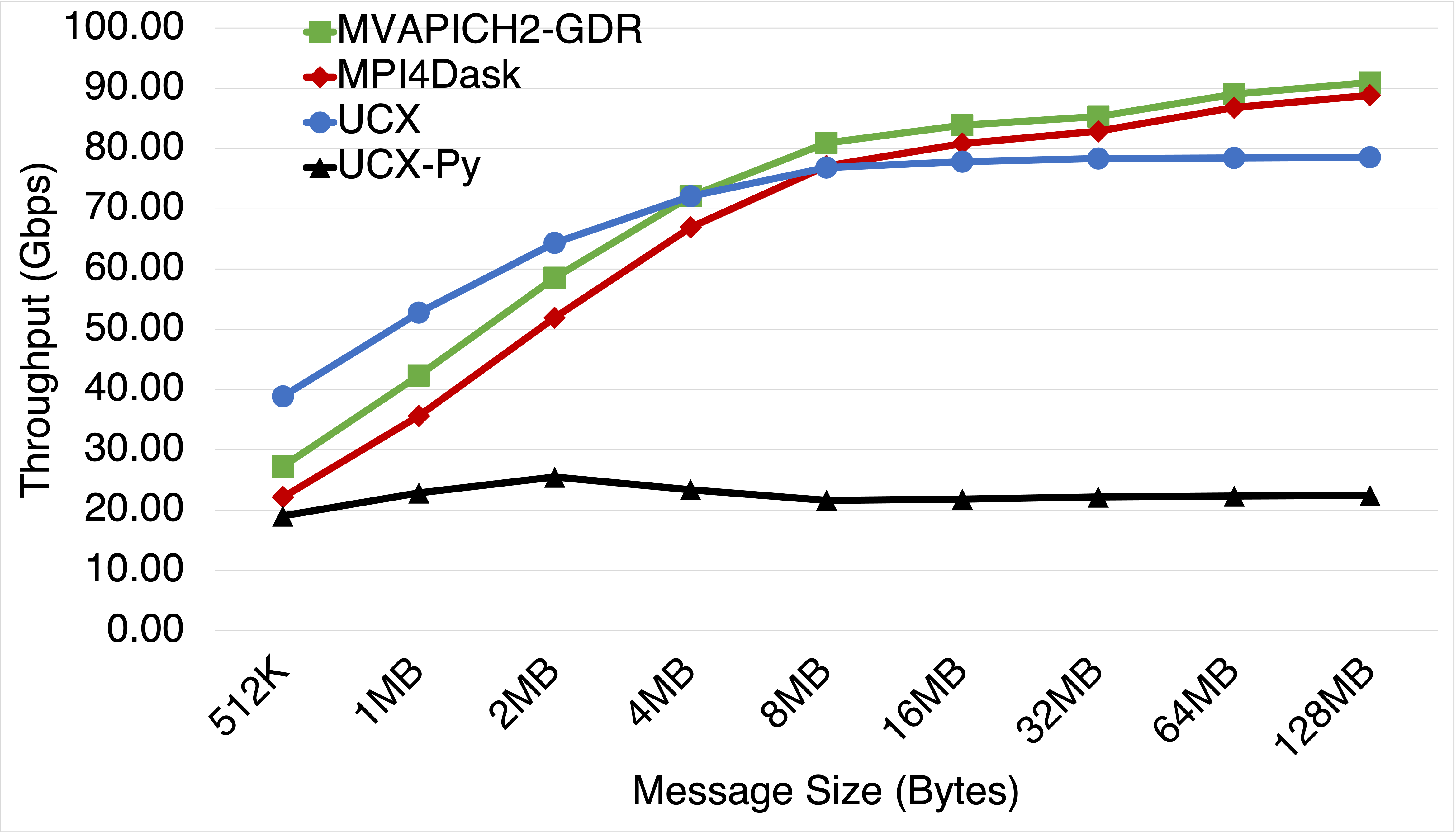
Bandwidth Comparison
Experimental Testbed: Each node in OSU-RI2 has two fourteen core Xeon E5-2680v4 processors at 2.4 GHz and 512 GB main memory. Each node has 1 NVIDIA V100 GPU with 32GB memory. The nodes support 16x PCI Express Gen3 interfaces and are equipped with Mellanox ConnectX-4 EDR HCAs with PCI Express Gen3 interfaces. The operating system used is CentOS 7.
This benchmark presents latency and bandwidth performance of MPI4Dask v0.2 communication co-routines and UCX-Py v0.17 communication co-routines using a Ping Pong benchmark that exchange data between inter-node GPUs. Also we add UCX v1.8.0 (Tag API) and MVAPICH2-GDR v2.3.5 to our comparisons for baseline performance. UCX was used with ucx_perftest to evaluate latency and throughput for UCX (Tag API). For MVAPICH2-GDR, we used the osu_latency test that is part of the OSU Micro-Benchmark Suite (OMB). UCX-Py was also evaluated using its own Ping-pong benchmark. UCX-Py has two modes of execution: 1) polling-based, and 2) event-based. The polling-based mode is latency-bound and hence more efficient than the event-based mode. The more efficient mode, polling-based, is used in these experiments.
Latency/Bandwidth Evaluation using the Ping-pong Benchmark
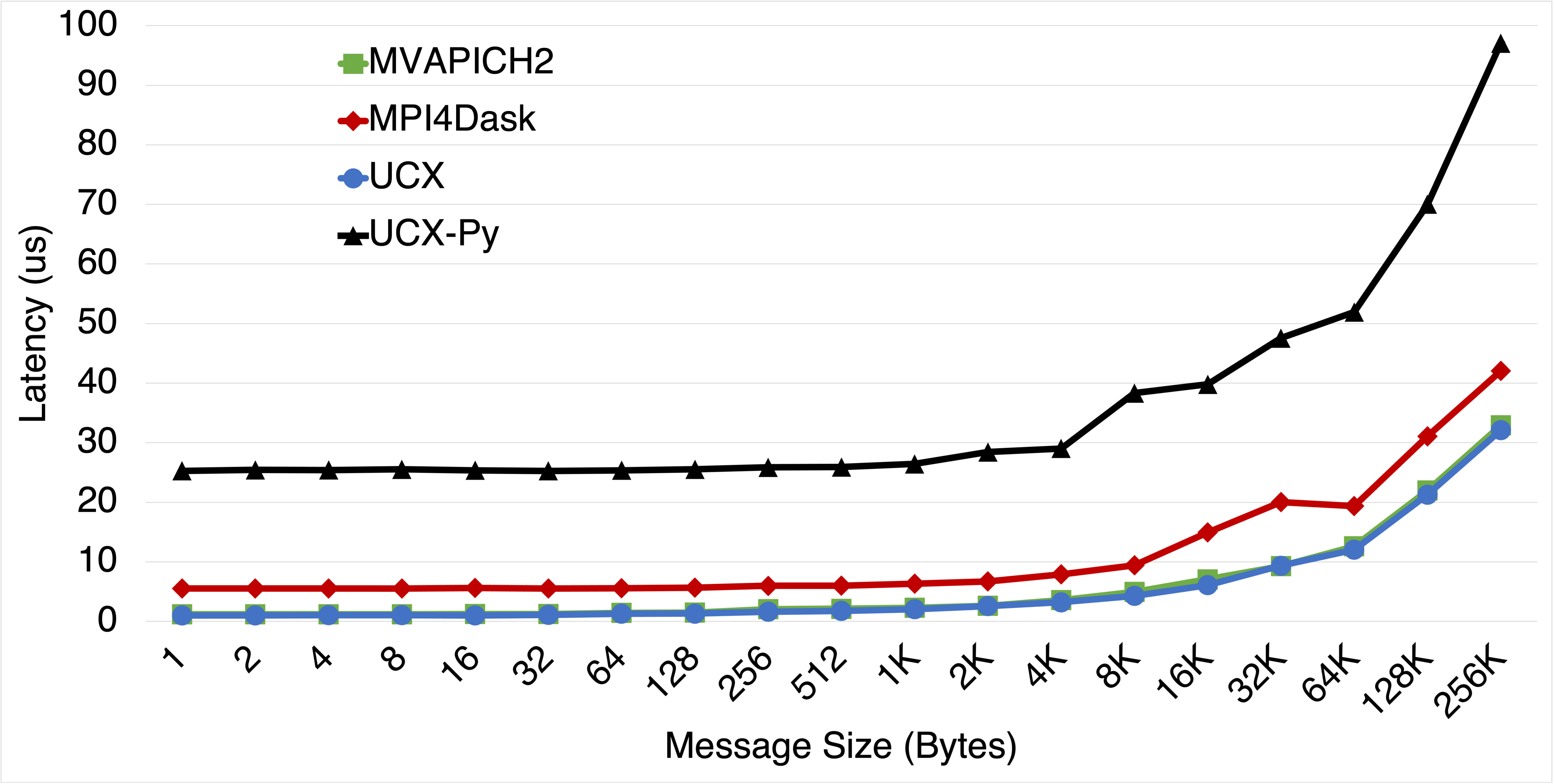
Latency Comparison
Bandwidth Comparison
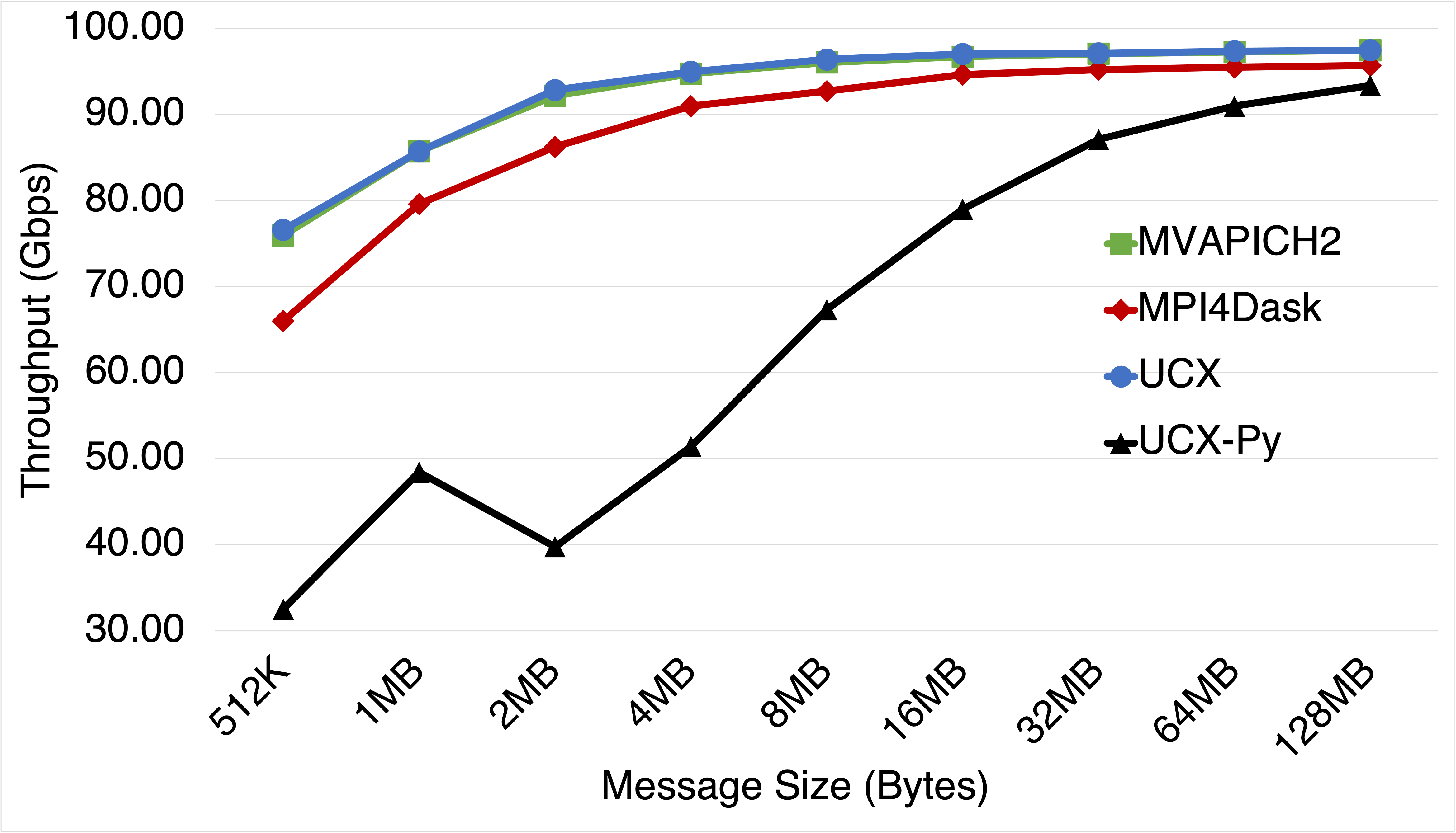
This benchmark presents latency and bandwidth performance of MPI4Dask v0.2 communication co-routines and UCX-Py v0.17 communication co-routines using a Ping Pong benchmark that exchange data between inter-node CPUs. Also we add UCX v1.8.0 (Tag API) and MVAPICH2-GDR v2.3.5 to our comparisons for baseline performance. UCX was used with ucx_perftest to evaluate latency and throughput for UCX (Tag API). For MVAPICH2-GDR, we used the osu_latency test that is part of the OSU Micro-Benchmark Suite (OMB). UCX-Py was also evaluated using its own Ping-pong benchmark. UCX-Py has two modes of execution: 1) polling-based, and 2) event-based. The polling-based mode is latency-bound and hence more efficient than the event-based mode. The more efficient mode, polling-based, is used in these experiments.

