

This benchmark creates a cuPy array and distributes its chunks across Dask workers. The benchmark perform submatrix dot production on these distributed chunks, and combine them together, forcing the GPU data to move around over the network. We compare the performance of MVAPICH2-GDR based communication device in the Dask Distributed library.
cuPy Array Dot Production Execution Time and Aggregate Worker Throughput
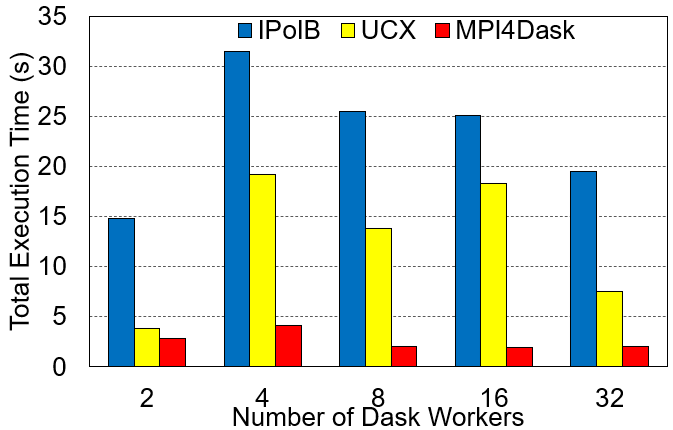
Execution Time
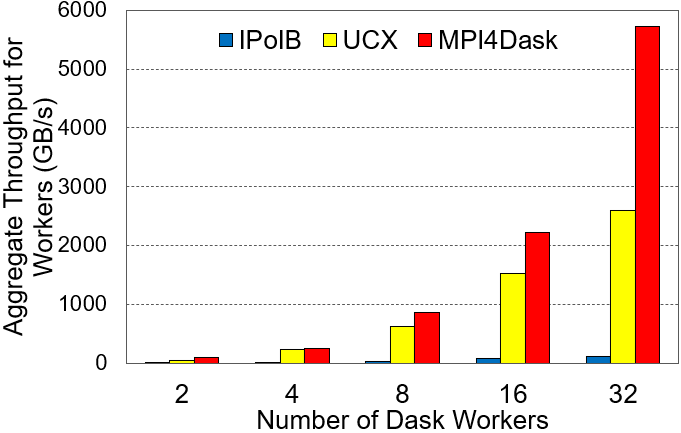
Aggregate Worker Throughput
Experimental Testbed: Each node in Cambridge Wilkes-3 System has two 32-core AMD EPYC 7763 processors with 1000 GB main memory. Each node has 4 NVIDIA A100 SXM4 GPUs with 80GB memory each. The nodes are equipped with Dual-rail Mellanox HDR200 InfiniBand.
The cuPy array dimensions are 32E3x32E3 and the chunk size is 4E3. The benchmark presents strong scaling results.
cuPy Array Dot Production Execution Time and Aggregate Worker Throughput
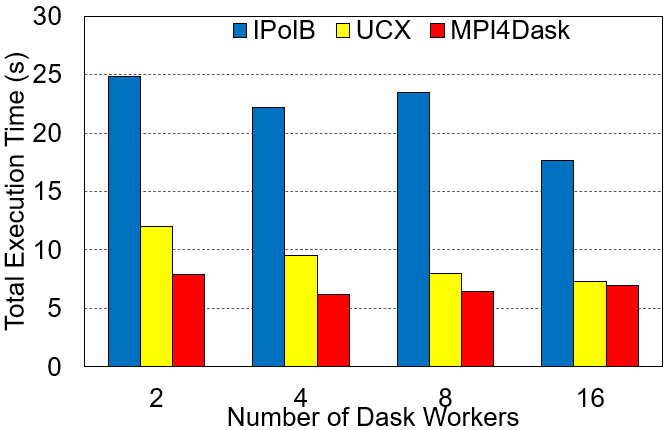
Execution Time
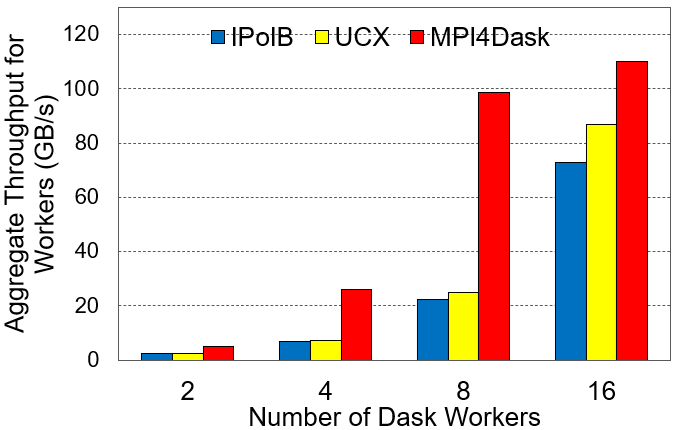
Aggregate Worker Throughput
Experimental Testbed: Each node in TACC Frontera System has two 28-core Intel Xeon Platinum 8280 with 192 GB main memory. The nodes are equipped with Dual-rail Mellanox HDR200 InfiniBand.
The cuPy array dimensions are 16E3x16E3 and the chunk size is 4E3. The benchmark presents strong scaling results.
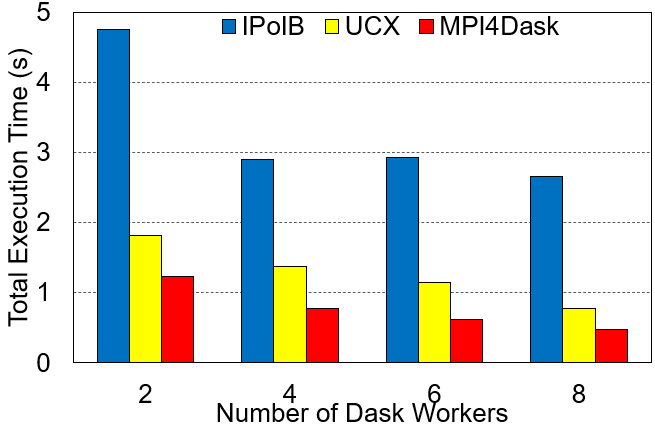
cuPy Array Dot Production Execution Time and Aggregate Worker Throughput
Execution Time
Aggregate Worker Throughput
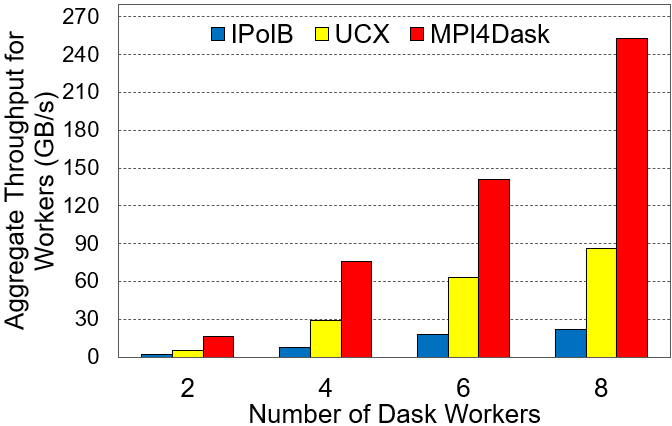
Experimental Testbed: Each node in RI2 System has two 28-core Intel Xeon E5 2680 with 512 GB main memory. The nodes are equipped with Mellanox EDR InfiniBand.
The cuPy array dimensions are 16E3x16E3 and the chunk size is 4E3. The benchmark presents strong scaling results.

